PythonとSelenium WebDriverを使ってChromeを自動操作する方法をわかりやすく説明します。
Pythonで出来ることは実に多様ですが、なかでもスクレイピングや今回のブラウザ操作はよく用いられる使い方の1つです。
今回は「東京駅+ラーメン」のように「場所+好きな食べ物」をグーグル検索し、好きな食べ物ごとに新規にタブを開く操作をPythonで自動化します。
まずは以下の動画で完成したプログラムの動作を確認してみてください。
コマンドプロンプトで「東京駅」と入力すると、「東京駅+カレー」、「東京駅+ラーメン」・・のように食べ物ごとに新しいタブを開いて検索します。ここでは、5品目分のタブを開いて、最後に先頭のタブに戻ります。この操作が20行に満たないPythonのコードで自動化できます。
では以下の目次の順序で説明します。
本記事の目次
- Seleniumモジュールのインストール
- Pythonプログラミング
- プログラムの実行
- 改良のポイント
- (参考)Chrome用のWebDriverを自分で準備する場合(Selenium4.6より前)
- 最後に
今回使用した環境はWindows10です。Google ChromeとPythonはインストール済みの状態で行いました。Pythonをインストールしていない場合は、以下のページを参考にインストールしてください。
Seleniumモジュールのインストール
pipを用いてSeleniumモジュールをインストールします。コマンドプロンプトを開いて、以下のコマンドを実行するとインストールできます。
C:¥Users¥Ichiro> py -m pip install -U selenium
既にインストール済みでも最新版をインストールするようにしてください(本記事では4.19を使用)。上のコマンドは-Uオプションが付いているので、インストール済みの場合でもアップグレードしてくれます。
インストールに成功すると以下のように「Successfully installed」に続いて、依存関係のライブラリと一緒に「selenium」が表示されます。
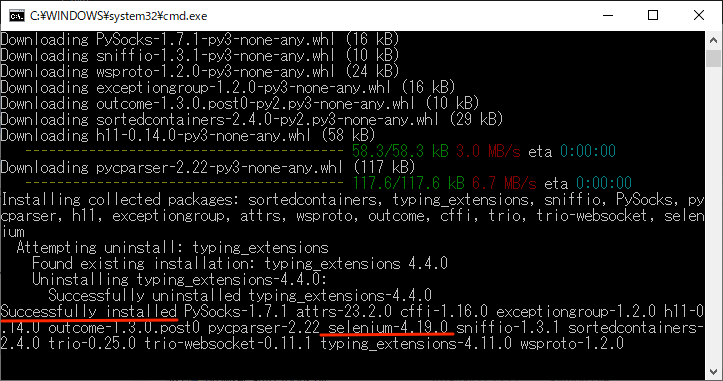
このSeleniumモジュールがクライアントとなりWebDriverを操作します。モジュールの詳細については以下のPyPIのページで確認できます。
https://pypi.org/project/selenium/
ちなみにPython以外にもJavaやC#のクライアントもあります。
pyコマンド(py.exe:Python Launcher)で実行していますが、Pythonインタプリタにパスを通して使用している場合は、pyをpythonに読み替えてください。
Pythonプログラミング
今回のプログラムは以下のコードだけです。場所と一緒に検索する好きな食べ物は「カレー,…,お好み焼き」の5品目です。もっと検索したい場合にはfavorite_foodsに追加します。
browser_auto_foods.py
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
chrome = webdriver.Chrome()
# 場所はコマンドプロンプトで直接入力
location = input("場所入力:")
# 好きな食べ物
favorite_foods = ["カレー", "ラーメン", "チャーハン", "とんかつ", "お好み焼き"]
for i, food in enumerate(favorite_foods):
if i > 0:
# 新しいタブ
chrome.execute_script("window.open('','_blank');")
chrome.switch_to.window(chrome.window_handles[i])
# グーグルを開く
chrome.get("https://www.google.co.jp")
# 検索ワード入力
search_box = chrome.find_element(By.NAME, "q")
search_words = location, food
search_box.send_keys(" ".join(search_words))
# 検索実行
search_box.send_keys(Keys.RETURN)
print(chrome.title)
# 先頭のタブに戻る
chrome.switch_to.window(chrome.window_handles[0])
コードの解説
WebDriverオブジェクトの作成
まず、webdriver.Chrome()でChrome用のWebDriverのオブジェクトを作成します。後は、このchrome変数にアクセスしてChromeを操作します。
新しいタブの開き方
新しいタブを開くには、JavaScriptのコード(window.open('','_blank');)をChromeに送信して実行します。他に「Ctrl+Tのキー」を送信する方法もありますが、今回はJavaScriptのコードを実行する方がうまく動作しました。
次に新しく開いたタブに移動します。i番目のタブはchrome.window_handles[i]で取得できるので、chrome.switch_to.window()のかっこ内に指定して実行すれば移動します。
検索ワードの入力と検索実行
プログラムで「検索ボックス」に検索ワードを入力するには、まずHTMLの構造を解読して該当する要素を特定します。グーグルの検索ボックスは、以下のようにname属性が"q"のinput要素です。
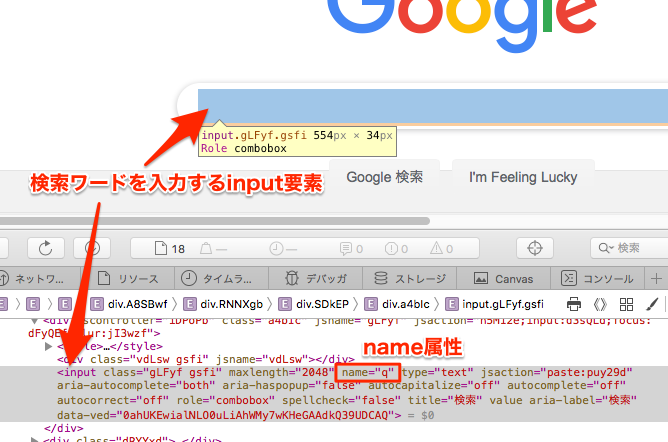
この要素を取得するにはfind_element()を用います。かっこ内の1つ目の引数にBy.NAME、2つ目の引数に"q"を指定することで、「name属性の値が”q”」の要素、つまり「検索ボックス」を取得できます。
search_box = chrome.find_element(By.NAME, "q")この「検索ボックス」に以下のコードで、検索キーワードを入力して、Enterキー(RETERN)を送信すれば、ブラウザで検索する操作を再現できます。
search_box.send_keys(" ".join(search_words))
search_box.send_keys(Keys.RETURN)
すべての検索が終了したら、先頭のタブに移動します。
chrome.switch_to.window(chrome.window_handles[0])HTML要素の特定方法
1つのホームページからHTML要素を特定するには、「CSSセレクタ」と「XPath」による2通りの方法があります。Seleniumモジュールは以下のドキュメントにあるようにどちらにも対応しています。
https://selenium-python.readthedocs.io/locating-elements.html
今回は、一般によく用いられるCSSセレクタの方を使用しました。CSSセレクタについては、以下の記事が参考になります。

プログラムの実行
WindowsにPythonをインストールするとデフォルトでは、拡張子.pyのファイルにはPythonランチャ(py.exe)が関連付いているので、ダブルクリックで実行できます。
そこで、今回はデフォルトでPythonがインストールされている状態を想定して、作成したプログラムのファイルbrowser_auto_foods.pyをダブルクリックして実行します。実行すると、
1)最初にコマンドプロンプトが起動し、
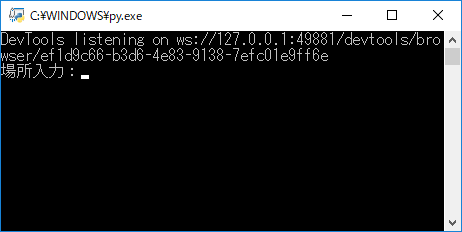
2)次にChromeが起動します。Chromeには以下のように、自動テストソフトウェア、つまりWebDriverで制御されていることが表示されます。
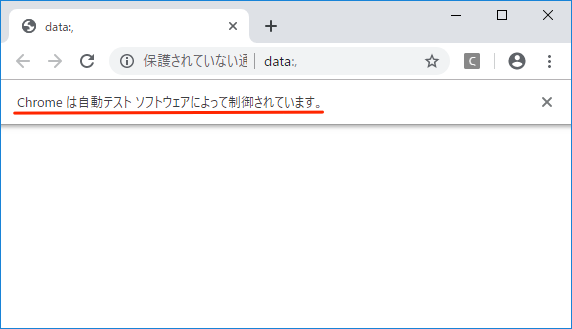
3)あとはコマンドプロンプトに場所を入力してEnterキーを押せばChromeで検索が始まり、次々に新しいタブに「場所 + 好きな食べ物」の検索結果が表示されます。
4)プログラムが完了すると以下のようにChromeは5つのタグが開いた状態になります。
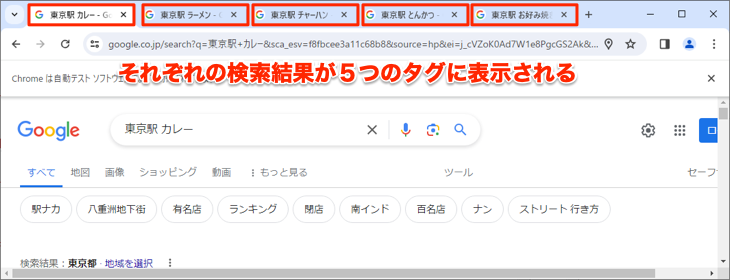
改良のポイント
Seleniumモジュールを利用すれば、他にも「リンクをクリックする」、「フォームに入力して送信する」、「スクリーンショットを撮る」、「ブラウザの戻るボタンをクリックする」など、様々な操作を自動化できます。
Seleniumモジュールの機能については以下の公式ドキュメントを参照してください。
https://selenium-python.readthedocs.io
(参考)Chrome用のWebDriverを自分で準備する場合(Selenium4.6より前)
以前は自分でWebDriverをダウンロードして、フォルダーに配置してパスを指定する必要がありましたが、Selenium4.6からは自動で読み込まれるので、現在は自分で準備する必要はありません。
以下では参考までに以前の自分で準備する方法の説明を残しておきます。
1.Chrome用のWebDriverのダウンロード
Selenium WebDriverは各種ブラウザごとにドライバが用意されているので、以下の方法でChrome用のWebDriverをダウンロードします。

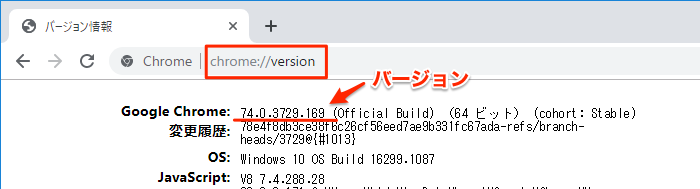
ここで、ドライバーはChromeのバージョンと一致したものをダウンロードします。Chromeのバージョンは、Chromeのアドレスの部分にchrome://versionと入力すると以下のように表示されます。以下の画面の場合はバージョン「74」です。
2.WebDriverの配置
今回は、上記の方法でWindowsの32ビット版のChrome用ドライバー「chromedriver-win32.zip」をダウンロードするとします。
このZIPファイルにはchromedriver.exeというファイルが1つだけ圧縮されています。解凍したら、以下のようにPythonプログラムと同じ階層にあるdriverフォルダを作成しその中に入れます。
# プログラムフォルダの中身
├ driver/
│ ├ chromedriver.exe # WebDriver
│
├ browser_auto_foods.py # 今回のPytyonプログラム
3.プログラムの改良
プログラムの前半部分を以下のように書き換えて、上記で配置したchromedriver.exeを読み込んで使用するようにします。
browser_auto_foods.py(ドライバーパス指定版)
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.service import Service
service = Service(executable_path="./driver/chromedriver.exe")
chrome = webdriver.Chrome(service=service)
...
Chromeが自動更新されたらドライバも新しくする必要がある
Chromeが自動更新されると、知らないうちにドライバのバージョンと一致しなくなることがあります。そうするとselenium.common.exceptions.SessionNotCreatedExceptionというエラーが発生します。その時は、バージョンが一致するドライバをダウンロードし直します。このように手動でドライバーを設置する方法は、メンテナンスに手間がかかります。通常は本記事のようにバージョン4.6以降の最新のSeleniumを使用することで、この手間を省きます。
最後に
実際にPythonで書いてみると、案外短いコードで実現できることに驚くことがあります。それがPythonの魅力でもあります。
プログラミングで何が出来るかは、文章を読んだだけではなかなか理解できませんが、まずはつくって動かしてみるとその価値がわかります。
コードの意味がわからなくても、まずは記事のまま動かしてみてください。プログラミングを始めたくなるはずです。
なお、以下の書籍でもSeleniumの使い方を基本から説明していますので、ぜひ参考にしてください。
