PDFのページ抜粋、結合、重ね合わせのようなPDFのページ操作ならば、PythonでPyPDF2を利用すれば簡単にプログラミングできます。例えば、フォルダ内のPDFを1つにまとめるプログラムなどがすぐに作れます。
しかし、PDFの中身のテキストをプログラムで読み取るのは大抵一筋縄ではいきません。日本語や帳票であればもっと難易度が上がります。
この方法ならどんなPDFでも大丈夫という決定版はありません。目的や原稿のPDFの状態により、適した方法を選択する必要があります。今回はその候補となる方法を紹介します。
本記事の目次
PyPDF2
PyPDF2 でもテキストを読み取れます。PyPDF2は以下のようにpipでインストールできます。
pip install PyPDF2以下のようにextractText()を実行すれば、テキストを抽出します。
import PyPDF2
with open("sample.pdf", "rb") as f:
reader = PyPDF2.PdfFileReader(f)
page = reader.getPage(0)
print(page.extractText())
PDFページの操作だけでなく、テキスト読み取りもPyPDF2ひとつで出来れば助かりますが、日本語に対応していないので、英数字の原稿に限られます(英数字でもフォントにより読み取れない文字があります)。
pdfminer.six
pdfminer.six を利用すれば、日本語のテキストを抽出できます。pdfminer.sixは以下のようにpipでインストールできます。
pip install pdfminer.sixpdfminer.sixをインストールすると、一緒にpdf2txt.pyというツールが以下のようなPythonのシステムのScriptsディレクトリにコピーされます。
例 C:/Users/Taro/AppData/Local/Programs/Python/Python37-32/Scripts/pdf2txt.py
このツールを以下のようなコードで呼び出せば、pdfファイルをテキストファイル(*.txt)に変換できます。当然コマンドラインからpdf2txt.pyを呼び出しても構いません。
import sys
from pathlib import Path
from subprocess import call
# pdf2txt.py のパス
py_path = Path(sys.exec_prefix) / "Scripts" / "pdf2txt.py"
# pdf2txt.py の呼び出し
call(["py", str(py_path), "-o extract-sample.txt", "-p 1", "extract-sample.pdf"])
試しに以下の厚生労働省の毎月勤労統計調査(平成30年9月分結果速報等) の1ページ目だけを読み取ってみます。
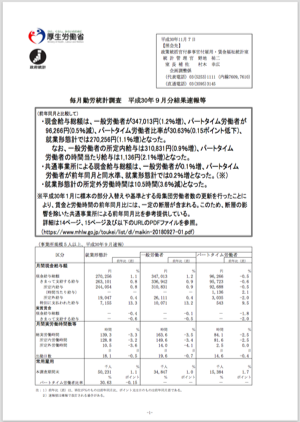
読み取り結果は以下のようになります(個人名と電話番号は一部アスタリスクで伏字にしています)。
【照会先】
政策統括官付参事官付雇用・賃金福祉統計室
統 計 管 理 官 ** **
室 長 補 佐 ** **
企画調整係
(代表電話) 03(****)1111 (内線7609,7610)
(直通電話) 03(****)3145
毎月勤労統計調査 平成30年9月分結果速報等
(前年同月と比較して)
・現金給与総額は、一般労働者が347,013円(1.2%増)、パートタイム労働者が
96,266円(0.5%減)、パートタイム労働者比率が30.63%(0.15ポイント低下)、
就業形態計では270,256円(1.1%増)となった。
なお、一般労働者の所定内給与は310,831円(0.9%増)、パートタイム
労働者の時間当たり給与は1,136円(2.1%増)となった。
・共通事業所による現金給与総額は、一般労働者が0.1%増、パートタイム
労働者が前年同月と同水準、就業形態計では0.2%増となった。(※)
・就業形態計の所定外労働時間は10.5時間(3.6%減)となった。
※平成30年1月に標本の部分入替えや基準とする母集団労働者数の更新を行ったことに
より、賃金と労働時間の前年同月比には、一定の断層が含まれる。このため、断層の影
響を除いた共通事業所による前年同月比を参考提供している。
詳細は14ページ、15ページ及び以下のURLのPDFファイルを参照。
(https://www.mhlw.go.jp/toukei/list/dl/maikin-20180927-01.pdf)
(事業所規模5人以上、平成30年9月速報)
区分
就業形態計
一般労働者
パートタイム労働者
前年比(差)
前年比(差)
前年比(差)
月間現金給与額
現金給与総額
きまって支給する給与
所定内給与
(時間当たり給与)
所定外給与
特別に支払われた給与
実質賃金
現金給与総額
きまって支給する給与
月間実労働時間数等
総実労働時間
所定内労働時間
所定外労働時間
出勤日数
常用雇用
本調査期間末
パートタイム労働者比率
円
270,256
263,101
244,054
-
19,047
7,155
-
-
時間
139.3
128.8
10.5
日
18.1
千人
50,231
%
30.63
%
1.1
0.8
0.8
-
0.4
13.3
-0.4
-0.6
%
-3.3
-3.2
-3.6
日
-0.5
%
1.1
ポイント
-0.15
円
347,013
336,942
310,831
-
26,111
10,071
-
-
時間
163.6
149.6
14.0
日
19.6
千人
34,847
%
-
%
1.2
0.9
0.9
-
0.4
13.2
-0.1
-0.5
%
-3.5
-3.4
-4.1
日
-0.7
円
96,266
95,723
92,688
1,136
3,035
543
-
-
時間
84.1
81.6
2.5
日
14.6
%
-0.5
-0.6
-0.5
2.1
-2.0
9.5
-1.8
-2.0
%
-2.5
-2.5
0.0
日
-0.4
%
1.0
ポイント
-
千人
15,384
%
-
%
1.7
ポイント
-
注:1)前年比(差)は、単位が%のものは前年同月比、ポイント又は日のものは前年同月差である。
2)速報値は確報で改訂される場合がある。
-1-
上から順に正確に読み取れているのがわかります。表の中でも、罫線で囲われたマスのなかを上から順に読み取っているのが特徴的です。
Apache Tika
Apache Tika というJavaで開発されたドキュメント分析・抽出ツールがあります。Tikaは、エクセルやPDFなど様々な形式のファイルからテキストを抽出できます。
Tikaを利用しても日本語のテキストをPDFから抽出できます。Tikaを利用するにはJavaの実行環境をインストールする必要があります。以下のページなどを参考にオープンソース版(AdoptOpenJDKなど)をインストールします。
AdoptOpenJDKの導入(法政大学 理工系学部 情報教育システム)
このTikaをPythonから使えるようにしたライブラリが、tika-python です。tika-pythonは以下のようにpipでインストールできます。
pip install tikatika-pythonライブラリを利用すると、初回実行時に自動的にTika本体(tika-server.jar)をリモートからダウンロードして使えるようにしてくれます。使い方は以下のサイトが参考になります。
Fast Text Extraction with Python and Tika(Medium.com)
pdfminer.sixの時と同じ厚生労働省の資料を以下のコードで読み取ってみます。
from tika import parser
file_data = parser.from_file("extract-sample.pdf")
text = file_data["content"]
print(text)
読み取り結果は以下のようになります(個人名と電話番号は一部アスタリスクで伏字にしています)。
(事業所規模5人以上、平成30年9月速報)
区分 就業形態計 一般労働者 パートタイム労働者
前年比(差) 前年比(差) 前年比(差)
月間現金給与額
円 % 円 % 円 %
現金給与総額 270,256 1.1 347,013 1.2 96,266 -0.5
きまって支給する給与 263,101 0.8 336,942 0.9 95,723 -0.6
所定内給与 244,054 0.8 310,831 0.9 92,688 -0.5
(時間当たり給与) - - - - 1,136 2.1
所定外給与 19,047 0.4 26,111 0.4 3,035 -2.0
特別に支払われた給与 7,155 13.3 10,071 13.2 543 9.5
実質賃金
現金給与総額 - -0.4 - -0.1 - -1.8
きまって支給する給与 - -0.6 - -0.5 - -2.0
月間実労働時間数等
時間 % 時間 % 時間 %
総実労働時間 139.3 -3.3 163.6 -3.5 84.1 -2.5
所定内労働時間 128.8 -3.2 149.6 -3.4 81.6 -2.5
所定外労働時間 10.5 -3.6 14.0 -4.1 2.5 0.0
日 日 日 日 日 日
出勤日数 18.1 -0.5 19.6 -0.7 14.6 -0.4
常用雇用
千人 % 千人 % 千人 %
本調査期間末 50,231 1.1 34,847 1.0 15,384 1.7
% ポイント % ポイント % ポイント
パートタイム労働者比率 30.63 -0.15 - - - -
注:1)前年比(差)は、単位が%のものは前年同月比、ポイント又は日のものは前年同月差である。
2)速報値は確報で改訂される場合がある。
平成30年11月7日
【照会先】
政策統括官付参事官付雇用・賃金福祉統計室
統 計 管 理 官 ** **
室 長 補 佐 ** **
企画調整係
(代表電話) 03(****)1111 (内線7609,7610)
(直通電話) 03(****)3145
(前年同月と比較して)
・現金給与総額は、一般労働者が347,013円(1.2%増)、パートタイム労働者が
96,266円(0.5%減)、パートタイム労働者比率が30.63%(0.15ポイント低下)、
就業形態計では270,256円(1.1%増)となった。
なお、一般労働者の所定内給与は310,831円(0.9%増)、パートタイム
労働者の時間当たり給与は1,136円(2.1%増)となった。
・共通事業所による現金給与総額は、一般労働者が0.1%増、パートタイム
労働者が前年同月と同水準、就業形態計では0.2%増となった。(※)
・就業形態計の所定外労働時間は10.5時間(3.6%減)となった。
※平成30年1月に標本の部分入替えや基準とする母集団労働者数の更新を行ったことに
より、賃金と労働時間の前年同月比には、一定の断層が含まれる。このため、断層の影
響を除いた共通事業所による前年同月比を参考提供している。
詳細は14ページ、15ページ及び以下のURLのPDFファイルを参照。
(https://www.mhlw.go.jp/toukei/list/dl/maikin-20180927-01.pdf)
-1-
pdfminer.sixとは異なり、下の表の部分が先に読み込まれています。表の部分は罫線の有無に関係なく、1行ずつ読み込まれているのが特徴です。
Javaのライセンスに留意
以前はオラクル社が提供するJavaを利用するのが一般的でしたが、2019年1月をもって無償サポートが終了しました。そのため、現在ではAdoptOpenJDKなどの無償版を利用することが多くなっています。
Tesseract OCR
請求書の控えなどをスキャナーで読み込み、PDF形式で保管しているケースはよくあります。その場合はデータは画像として保存されているので、テキストを読み取るにはOCRが必要です。
PDFをOCRで認識させるには、PDFの原稿を画像に変換して用います。また、画像データのPDFの場合は画像だけを抜き出して使うこともできます。
OCRにはTesseract (テッセラクト)というオープンソースのOCRを利用します。Tesseractは事前にインストールする必要があります。インストール方法は以下のサイトが参考になります。

Tesseract自身はPythonとは関係ないツールですので、PyOCR というライブラリから動かします。PyOCRは以下のようにpipでインストールできます。
pip install pyocrPyOCRを用いたOCRの方法は以下のページで詳しく説明しています。画像データで読み取る位置を指定できるので、請求書や証明書の番号の読み取りに便利です。
PDFから画像データを抜き出して使う方法
PDFの中の画像データを使う場合には、pdfminerで抜き出してからPillow というライブラリで読み込む必要があります。その作業も含めて、全体の手順は以下のサイトに非常に分かりやすくまとめられています。
毎月数時間を要していたスキャンデータ整理をOCRで自動化した(Hatena Blog)
最後に
以上より、PDFからテキストを読み取るには、以下の方法が考えられます。
| PDF原稿の種類 | 読み取り方法の候補 |
|---|---|
| 英数字のみのテキストのPDF | PyPDF2 |
| 日本語を含むテキストのPDF | pdfminer.six、Apache Tika |
| 画像データのPDF、帳票PDF | Tesseract |
帳票PDFについては、テキストデータのPDFであっても、位置を指定した方が対象のデータを読み取りやすいので、画像データに変換してからOCRで読み取る方がよいケースが多いと考えられます。
このようにPDFの中身を読み取るにはいくつか方法がありますが、自動化するのは結構な手間がかかります。なるべく、元データがある場合は、PDF形式にして保管するのは避けるのが得策です。