今回はPDFを画像ファイル(JPEG、PNG)にPythonで変換する方法をご紹介します。
PDFを画像ファイルに変換するには、通常は有料のAdobe® Acrobat®などのソフトを用いますが、Pythonなら無料で入手できるライブラリで実施できます。
PythonでPDFを画像に変換できれば、PDFの書類をOCRで文字認識したり、多量のPDFファイルをプレビューしやすくするなど、PDFをもっと効率化に利用できるようになります。
本記事の目次
pdf2imageのインストール
今回はPythonでPDFを画像に変換するのに「pdf2image」というライブラリを使用します。pdf2imageはPyPIで公開されている ので、以下のようにpipで簡単にインストールできます。
C:¥Users¥Taro> py -m pip install pdf2image
pdf2imageは以下のようにpip showで情報を確認するとPillowという画像処理のライブラリを必要とします。Pillowがインストールされていない場合は一緒にインストールしてくれます。
C:¥Users¥Taro> py -m pip show pdf2image
Name: pdf2image
Version: 1.11.0
Summary: A wrapper around the pdftoppm and pdftocairo command line tools to convert PDF to a PIL Image list.
Home-page: https://github.com/Belval/pdf2image
Author: Edouard Belval
Author-email: edouard@belval.org
License: MIT
Location: c:\users\taro\appdata\local\programs\python\python37-32\lib\site-packages
Requires: pillow
Required-by:
popplerのダウンロード
pdf2imageは「Poppler」というフリーのPDFコマンドラインツールを背後で用います。そのため、Popplerをダウンロードしておく必要があります。
PopplerはPDF出力ライブラリとしてLinuxでよく用いられています。そこにはPDFの情報取得、形式変換、編集などを可能にするユーティリティが含まれており、pdf2imageでは「pdftoppm」という画像に変換するツールを利用しています。
今回はWindowsでプログラミングするので、以下のWebページからWindows版のPopplerをダウンロードします。
このWebページには「Release ??.??.?-?.zip」のようなリンクがあるので、そこをクリックするとダウンロードできます。
ダウンロードしたファイルは「Zip形式」で圧縮されていますので、解凍してください。
解凍したフォルダの「Libraryフォルダ」内には、bin, include, lib, shareのフォルダが含まれています。これらを以下で説明するpopplerフォルダにコピーします。
プロジェクトフォルダ構成
今回は以下のようなフォルダ構成でプログラムを作成・実行します。
- PdfToImage
- image_file
- pdf_file
- pdf3009p.pdf
- poppler
- bin
- include
- lib
- share
- pdf_to_image.py
プログラムファイル(pdf_to_image.py)と以下の3つのフォルダを配置します。
- image_fileフォルダ:PDFから変換した画像ファイルを保存する場所
- pdf_fileフォルダ:原稿のPDFファイルをここに入れておく
- popplerフォルダ:ダウンロードしたpopplerの中身をここにすべてコピーする
今回はPDFのサンプルとして厚生労働省の毎月勤労統計調査(平成30年9月分結果速報等)の概要 を利用します。このPDFファイル(pdf3009p.pdf)は以下のように16ページあります。
pdf3009p.pdf

このPDFを1ページずつ画像に変換します。
プログラミング(JPEG、PNGへの変換)
以下のようにpaf2imageライブラリのconvert_from_path()関数に、PDFファイルのパスと解像度(単位:dpi)を指定して実行すると画像に変換してくれます。
convert_from_path()関数は、1ページごとの画像のリストを返すので、ループして1ページずつ保存します。この画像はPillowライブラリのImage型なのでsave()メソッドを呼び出せば保存できます。2つめのパラメータで画像形式(”JPEG”,”PNG”等)を指定できます。
import os
from pathlib import Path
from pdf2image import convert_from_path
# poppler/binを環境変数PATHに追加する
poppler_dir = Path(__file__).parent.absolute() / "poppler/bin"
os.environ["PATH"] += os.pathsep + str(poppler_dir)
# PDFファイルのパス
pdf_path = Path("./pdf_file/pdf3009p.pdf")
# PDF -> Image に変換(150dpi)
pages = convert_from_path(str(pdf_path), 150)
# 画像ファイルを1ページずつ保存
image_dir = Path("./image_file")
for i, page in enumerate(pages):
file_name = pdf_path.stem + "_{:02d}".format(i + 1) + ".jpeg"
image_path = image_dir / file_name
# JPEGで保存
page.save(str(image_path), "JPEG")
ここで、poppler/binフォルダにあるユーティリティをpdf2imageライブラリが利用できるようにするため、PATHを通しておく必要があります。システムの設定で環境変数PATHに追加しても構いませんが、ここではos.environ["PATH"]に追加することでに一時的にPATHを通しています。この方がシステムのPATHをシンプルに保てます。
プログラムを実行すると以下のように16個のJPEGファイルが作成されます。
pdf3009p_01.jpeg 〜 pdf3009p_16.jpeg
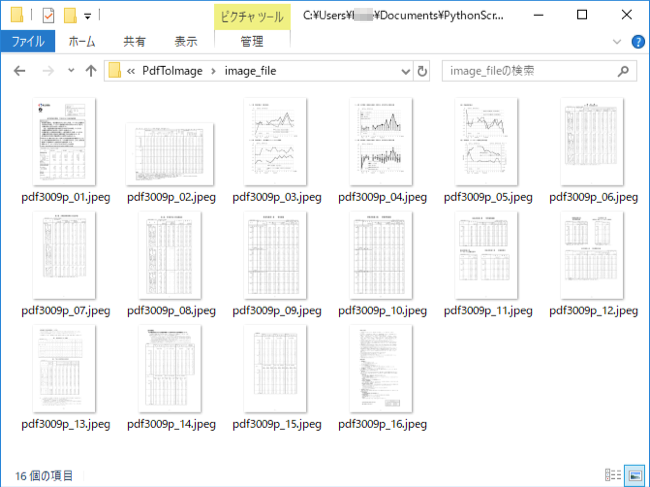
原稿のPDFと比較しても精度良く変換されているのがわかります。
PNG形式に変換したい場合
PNG形式で画像を保存したい場合は、以下のように拡張子を".png"に、保存形式のパラメータを"PNG"に書き換えます。
...
image_dir = Path("./image_file")
for i, page in enumerate(pages):
file_name = pdf_path.stem + "_{:02d}".format(i + 1) + ".png"
image_path = image_dir / file_name
# PNGで保存
page.save(str(image_path), "PNG")
マルチページのTIFFに変換したい場合
16ページを16個の画像ファイルでなく、1つのTIFF形式のファイルに変換することも可能です。それには以下のようにコードを書き換えます。
...
image_dir = Path("./image_file")
tiff_name = pdf_path.stem + ".tif"
image_path = image_dir / tiff_name
pages[0].save(str(image_path), "TIFF", compression="tiff_deflate", save_all=True, append_images=pages[1:])
このように、1ページ目(pages[0])でsave()メソッドを呼び出します。その時に、パラメータとして、save_allはTrue、append_imagesには2ページから最後までの画像リストを指定します。
圧縮方式(compression)を指定しないこともできますが、ファイルサイズが膨大になるので指定するようにします。ここでは、データロスのない圧縮方式("tiff_deflate")を指定しています。他の方式は以下のPillow公式ドキュメントを参照してください。
Pillowドキュメント Image file formats ▶ Saving Tiff Images
様々に応用できます
PDFから画像への変換がプログラムで可能になれば、応用範囲がグッと広がります。
例えば、各PDFファイルの1ページ目だけを画像にすれば、PDFが大量にあってもサムネイル画像を作成できます。ちなみに、先頭のページだけを画像に変換するにはconvert_from_path()関数でオプションとしてlast_page=1を指定します。
また、PDFの帳票の決まった位置にある文字を読み取りたい場合は、PDFを苦心して解析するよりも、画像に変換してからOCRで認識した方がうまく処理できる場合があります。
ぜひ様々なアイデアを試してみてください。