OCRはオフィスワークの自動化に欠かせないテクノロジーですが、自分でプログラミングするには敷居の高い分野でもありました。
しかし、オープンソースのOCRエンジンの普及によりかなり身近になりました。今回はその代表格であるGoogleのTesseractを用いて、PythonでOCRを実行するプログラムを作成してみます。
本記事の目次
Tesseractのインストール
OCRを行うには、事前にOCRエンジンをインストールしておく必要があります。ここでは、Googleが開発しているオープンソースのOCRエンジン「Tesseract」を利用します。今回は以下のページの方法でWindowsにインストールしておきます。

PyOCRのインストール
TesseractをインストールしておけばコマンドからOCRを実行できる状態になりますが、Pythonのライブラリから操作するとさらに使いやすくなります。
ここでは、PyPIで公開されている 「PyOCR」というライブラリを利用します。インストールは以下のようにpipで簡単にインストールできます。
> py -m pip install pyocr
# または環境に応じて以下のコマンドを用いる
> python -m pip install pyocr
> python3 -m pip install pyocr
PyOCRをインストールすると画像処理を行える「Pillow」というライブラリも一緒にインストールされます。
OCRを行うサンプル画像
Tesseractの確認テストでは背景がないシンプルな画像を使いましたが、ここでは背景に模様がある画像を用います。OCRによる文字認識の難易度は高くなります。
今回は出入国在留管理庁ホームページから以下の在留カードのサンプルを利用させていただきます。背景に模様があるので認識精度を上げるには少し工夫が必要です。
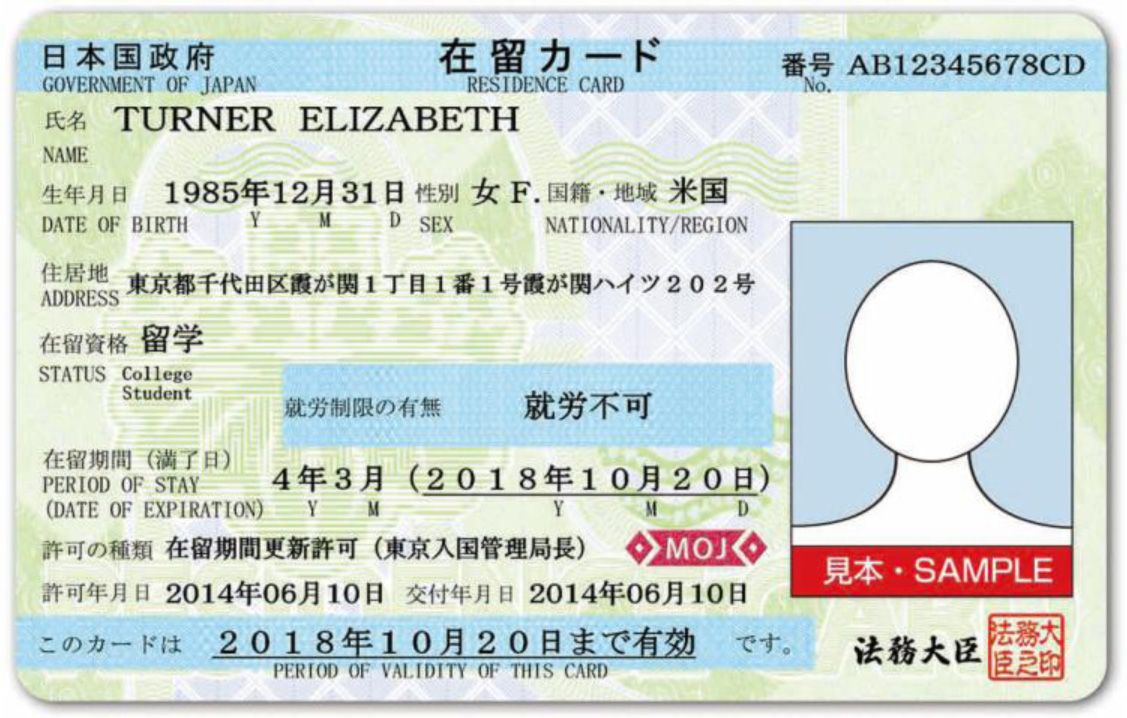
Pythonのコードと同じ階層のcard_imageフォルダにzairyucard_omote.jpgというファイル名で保存しておきます(画像の上で右クリックして表示されるメニューから保存できます)。
画像の出典
出入国在留管理庁ホームページ
http://www.immi-moj.go.jp/tetuduki/zairyukanri/whatzairyu.html
出入国在留管理庁ホームページのコンテンツの利用については以下のページを参照してください。
http://www.immi-moj.go.jp/copyright2.html
元の画像のままOCRを実行
まず元の画像を何も加工しないで、そのままOCRで文字認識させてみます。コードは以下のようになります。
# ocr_card.py
import os
from PIL import Image
import pyocr
import pyocr.builders
# 1.インストール済みのTesseractのパスを通す
path_tesseract = "C:\\Program Files (x86)\\Tesseract-OCR"
if path_tesseract not in os.environ["PATH"].split(os.pathsep):
os.environ["PATH"] += os.pathsep + path_tesseract
# 2.OCRエンジンの取得
tools = pyocr.get_available_tools()
tool = tools[0]
# 3.原稿画像の読み込み
img_org = Image.open("./card_image/zairyucard_omote.jpg")
# 4.OCR実行
builder = pyocr.builders.TextBuilder()
result = tool.image_to_string(img_org, lang="jpn", builder=builder)
print(result)
Tesseract + PyOCR プログラミングの基本的な手順
上記のコードは以下の4つの手順で処理しています。これが Tesseract + PyOCR でプログラミングする時の基本的な流れです。以降のコードもこの手順で処理します。
- Tesseractのパスを通す(または、通しておく)
- OCRエンジン(Tesseract)をPyOCRで取得
- 原稿の画像をPIL.Imageで読み込む
- Builderを指定してOCR実行
1. OCRを実行するには、Tesseractのインストール先のパスが通っている必要があります。Windowsの「環境変数」でPATHに登録しても構いませんが、ここではos.environを用いてコードで一時的にパスを通します。
2. pyocr.get_available_tools()で使用可能なOCRエンジンを取得できます。今回はTesseractしかインストールしていない状態なので、tools[0]で取得できます。
3. 画像の読み込みには、PyOCRと一緒にインストールされたPillowを用います。from PIL import ImageでインポートしたImageからopen()関数を呼び出します。
4. OCRで文字認識を行うにはimage_to_string()関数を呼び出します。この関数には、画像、言語の他に、builderとして文字認識用のTextBuilder()を指定します。
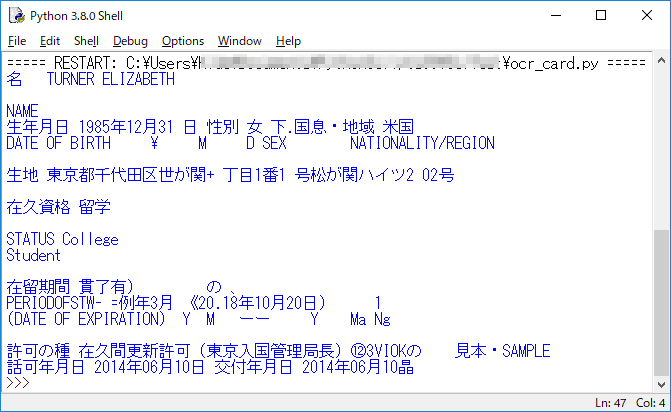
認識結果
以下のように背景が水色の部分が認識できていないのがわかります。一部分だけ塗り潰された背景があると、そこはうまく読み取れないようです。
元の画像を加工してOCRを実行
背景による影響を軽減するために、画像を加工します。ここでは、以下のように黒っぽい色だけを残す処理を行います。

処理は以下のようにRGBの値がどれかが169を超える場合は、白色(RGB = 255,255,255)に置き換えます。RGBは色を赤緑青の三色で表します。全般に数値が0に近くなると暗い色になります。
# ocr_card_filter.py
import os
from PIL import Image
import pyocr
import pyocr.builders
# インストール済みのTesseractのパスを通す
path_tesseract = "C:\\Program Files (x86)\\Tesseract-OCR"
if path_tesseract not in os.environ["PATH"].split(os.pathsep):
os.environ["PATH"] += path_tesseract
# OCRエンジンの取得
tools = pyocr.get_available_tools()
tool = tools[0]
# 原稿画像の読み込み
img_org = Image.open("./card_image/zairyucard_omote.jpg")
img_rgb = img_org.convert("RGB")
pixels = img_rgb.load()
# 原稿画像加工(黒っぽい色以外は白=255,255,255にする)
c_max = 169
for j in range(img_rgb.size[1]):
for i in range(img_rgb.size[0]):
if (pixels[i, j][0] > c_max or pixels[i, j][1] > c_max or
pixels[i, j][0] > c_max):
pixels[i, j] = (255, 255, 255)
# OCR実行
builder = pyocr.builders.TextBuilder()
result = tool.image_to_string(img_rgb, lang="jpn", builder=builder)
print(result)
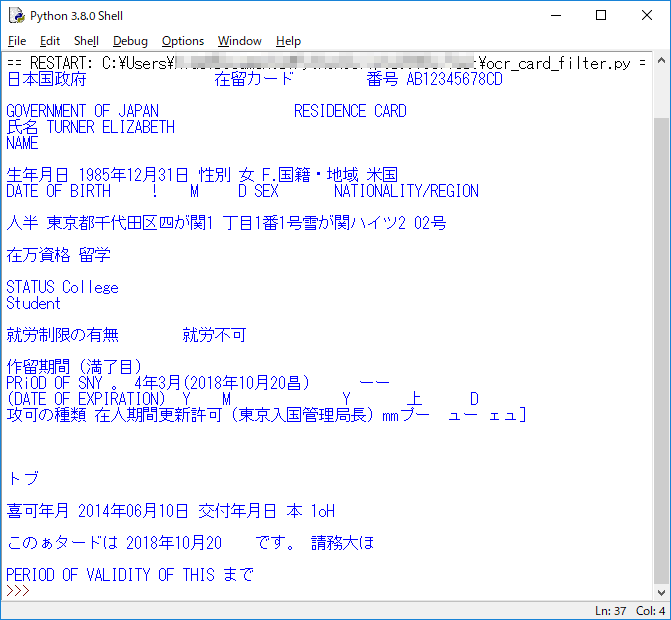
認識結果
かなり良くなりました。1行目の「日本国政府 在留カード 番号 AB12345678CD」が正確に読み取れるようになったのは大きな成果です。しかし、「霞が関」はかなり難易度が高そうです。
画像の一部を切り抜いてOCRを実行
全文を認識できなくても一部だけを正確に認識させたいケースはよくあります。例えば、以下のように「番号」の部分です。この部分だけを正確に読み取れればファイル管理などに応用できます。
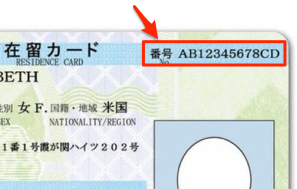
そこで以下のコードで番号の部分だけを切り抜いてOCRを行ってみます。
# ocr_card_crop.py
import os
from PIL import Image
import pyocr
import pyocr.builders
# インストール済みのTesseractのパスを通す
path_tesseract = "C:\\Program Files (x86)\\Tesseract-OCR"
if path_tesseract not in os.environ["PATH"].split(os.pathsep):
os.environ["PATH"] += path_tesseract
# OCRエンジンの取得
tools = pyocr.get_available_tools()
tool = tools[0]
# 原稿画像の読み込み
img_org = Image.open("./card_image/zairyucard_omote.jpg")
# 番号の部分を切り抜き
img_box = img_org.crop((770, 40, 1100, 90))
# OCR実行
builder = pyocr.builders.TextBuilder()
result = tool.image_to_string(img_box, lang="jpn", builder=builder)
print(result)
画像を切り抜くには、crop()メソッドを用います。かっこ内に切り抜く座標を(左上のX, 左上のY, 右下のX, 右下のY)でタプルで指定します。画像の座標は以下のように左上が原点になります。
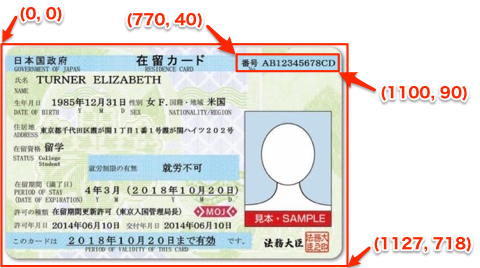
切り抜いた画像は以下のようになります。

画像の座標を調べる方法
Windowsのアクセサリにある「ペイント」というソフトで画像を開くと、マウスポインタの位置の座標が左下に表示されます。
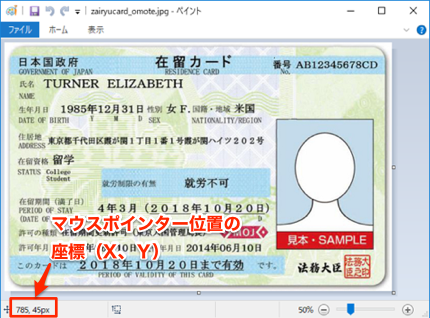
ペイントソフトの開き方は以下のサイトを参考にしてください。
認識結果
以下のように番号を正確に読み取れます。このように背景を加工しないでも、番号の部分だけ切り抜けば正確に読み取れることができます。

最後に
OCRの技術は、まだまだ奥が深いです。例えば、機械学習によりもっと精度を向上させることもできます。一方そこまで精度を追求しなくても、今回のように画像を加工したり、必要な部分だけを切り抜いて実務に用いることは十分可能です。
ぜひ実際のケースで試行錯誤しながら試してみてください。