OCRをPythonで操作できれば大量の紙資料の読み取りも自動化できます。特に郵便番号や請求書番号など定型書類の番号を読み取る作業は代表的な活用例です。
普段のオフィスワークではOCRソフトウェアを用いるのが一般的です。しかし、こららのソフトウェアはPythonから操作できません。そこで、OCRエンジンのみを利用してPythonから操作します。
代表的なOCRエンジンにGoogleがオープンソースで開発している「Tesseract 」があります。
今回はPythonでOCRを操作するための準備として、このTesseractをWindowsにインストールする手順を説明します。
本記事の目次
Tesseractのダウンロード
LinuxやMacではレポジトリからインストールできますが、Windowsについてはドイツのマンハイム大学図書館提供のインストーラーを利用できます。マンハイム大学図書館はTesseractで歴史的な新聞の文字認識を行っています。
以下のページにアクセスしてWindows用のインストーラーをダウンロードします。32bit版と64bit版がありますが、今回は32bit版をダウンロードします。
Home · UB-Mannheim/tesseract Wiki · GitHub
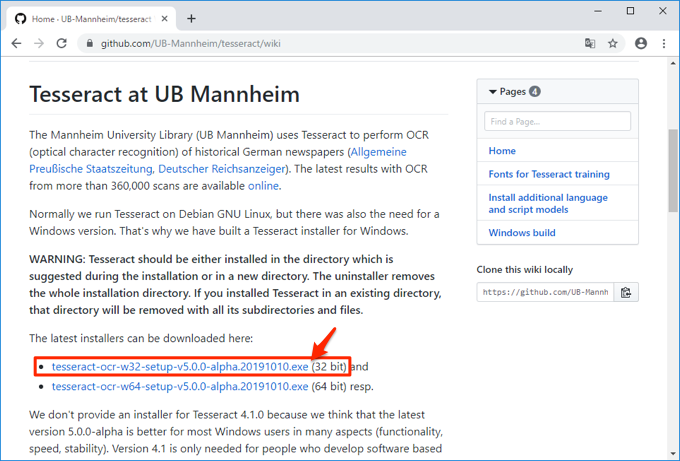
最新バージョンに読み替えてください
ここでは執筆時点で最新の5.0.0-alphaをダウンロードしていますが、随時新しいバージョンが公開されていますので、読み替えてください。
Tesseractのインストール
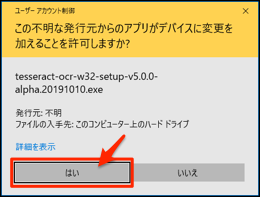
ダウンロードしたインストーラー(ここでは、tesseract-ocr-w32-setup-v5.0.0-alpha.20191010.exe)を実行すると以下のダイアログが表示されるのではいをクリックします。
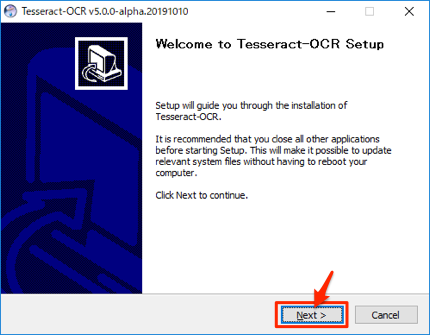
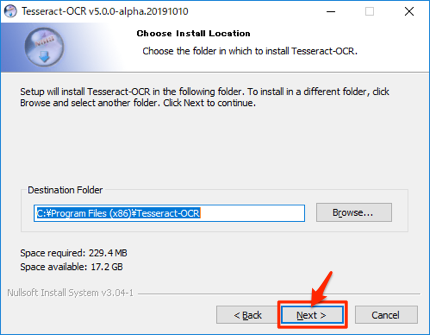
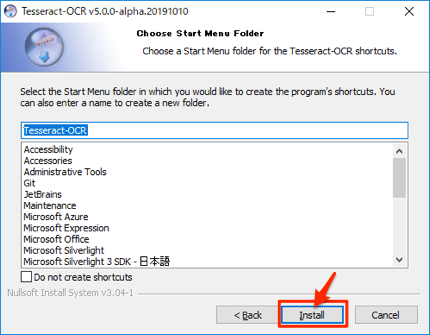
インストーラーが起動するので、デフォルトのままクリックして進めます。
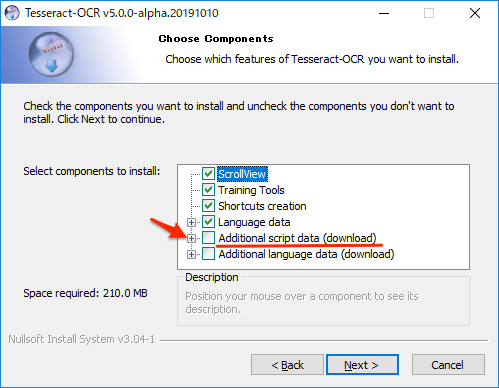
追加スクリプトデータの選択
以下の画面が表示されたらAdditional script data (download)の+をクリックして展開します。
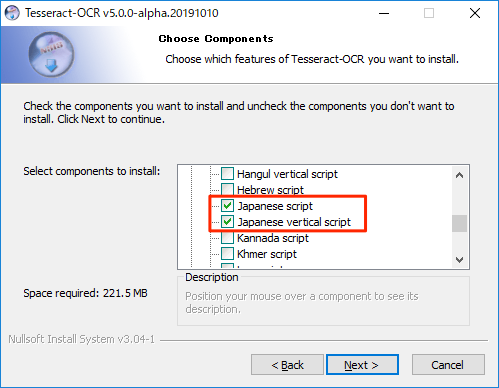
展開した項目から以下のJapanese ~の項目をチェックします。
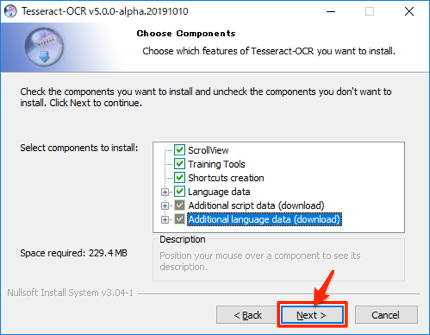
追加言語データの選択
次にAdditional language data (download)の+をクリックして展開します。

展開した項目から以下のJapanese ~の項目をチェックします。
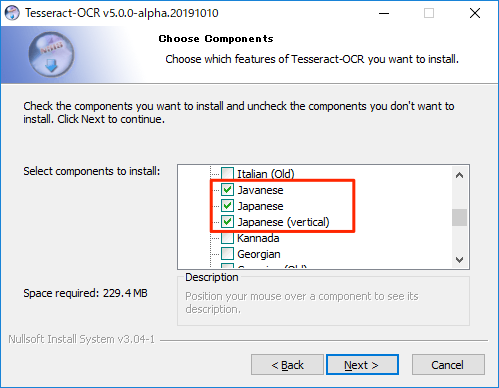
追加のスクリプトとデータを選択したら、Nextをクリックします。
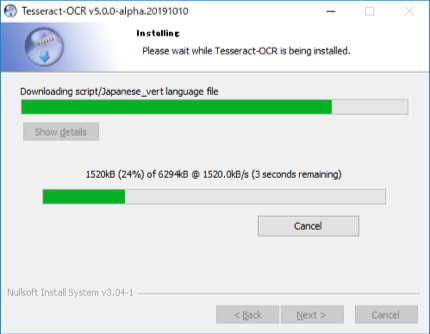
インストール実行
インストール完了
OCRの動作テスト
以下の画像ファイル(ocr-test.png)を文字認識してみます。画像上で「右クリック▶保存」してご利用ください。

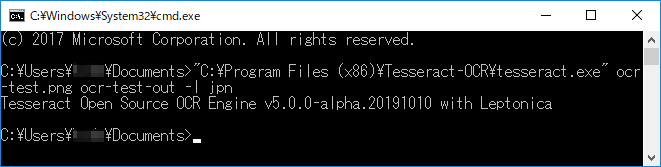
上記の画像をドキュメントフォルダに保存して、コマンドプロンプトに以下のコマンドを実行すると文字認識を実行します。-l jpnは日本語で認識させるためのオプションです。
C:\Users\Ichiro\Documents>"C:\Program Files (x86)\Tesseract-OCR\tesseract.exe" ocr-test.png ocr-test-out -l jpn
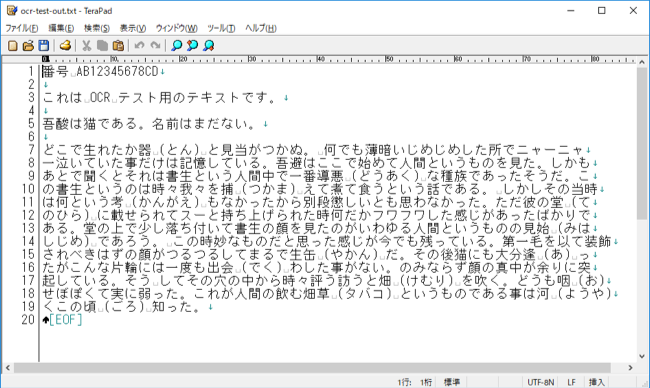
出力されたファイル(ocr-test-out.txt)を開くと以下のように文字が認識されているのを確認できます。「頓」や「輩」のように画数が多い漢字は誤認されやすいですが、その他は概ね認識できています。
コマンドの詳細については以下のページから参照できます。
Tesseract Wiki – Running Tesseract
次のステップ
以上でTesseractをインストールし動作を確認できたので、次はPythonでプログラミングします。以下のページで詳しく説明していますので、参考にしてください。
