スクレイピングの定番の方法と言えば「requests + BeautifulSoup」の組み合わせです。一般的はWebページであれば、大抵はスクレイピングできます。
しかし、この方法で読み取れないWebページに遭遇することがあります。特にYahoo!やTwitterなど頻繁に更新されるサイトによくあります。
その原因は、「ダウンロードしたHTMLファイル」と「ブラウザに表示されるHTML」が異なるからです。そのため、requestsでサーバーから直接ダウンロードしたHTMLファイルをBeautifulSoupで解読してもブラウザで見ている内容と違うのでスクレイピングできません。
Yahoo! JAPANが運営しているYahoo!リアルタイム検索 はまさにリアルタイムで更新されていますが、requests + BeautifulSoupではスクレイピングできません。今回はこのページを題材にスクレイピングする方法を説明します。
この記事の目次
なぜダウンロードしたHTMLファイルと内容が異なるのか
従来からの一般的なWebページの配信方法は、Webサーバーで最終的なHTMLを生成してからクライアントにレスポンスします。
しかし、ページ全部をサーバーで生成するため、頻繁に更新するページではサーバーのコストがかかります。そこで、ページの生成はブラウザで行いサーバーの負担を減らす方法が考えられました。
よくある仕組みは、テンプレートだけのHTMLをダウンロードしておき、内容を別個にダウンロードしながらブラウザのエンジンで最終的なHTMLを構築する方法です。
このような方法を採用しているWebページでは、requestsで取得されるのはテンプレートのHTMLファイルであり、最後に表示されるHTMLとは別物です。
ブラウザで実行されるプログラミング言語「Javascript」
最初にダウンロードされるHTMLファイルには、Javasciptというブラウザで実行可能なプログラミング言語で記述されたコードが含まれています。このコードがブラウザで実行されてページが組み上げられます。
ブラウザの表示内容を取得するには?
この問題を解決するには、ブラウザのエンジンでHTMLを生成させる必要があります。よく用いられるのは以下のページのようにSelenium WebDriverでブラウザを操作する方法です。
実際にChromeなどのブラウザをPythonで操作するので、ブラウザと同じ表示内容を取得できます。しかし、専用のドライバーを準備する必要があるなど少し面倒なところがあります。
requests-html ライブラリ
そこで、今回は簡単に利用できるrequests-html というライブラリを使用します。以下のようにpipを用いてインストールできます。
> py -m pip install --upgrade pip
> py -m pip install requests-htmlrequests-htmlは以下のように、requestやBeautifulSoup(bs4)に依存したライブラリです。つまり、内部でこれらのライブラリを利用しています。なかでもpyppeteer により「インターフェースなしのブラウザ(ヘッドレス)」を使うことでブラウザの表示内容を取得できます。
> py -m pip show requests-html
Name: requests-html
Version: 0.10.0
Summary: HTML Parsing for Humans.
Home-page: https://github.com/kennethreitz/requests-html
Author: Kenneth Reitz
Author-email: me@kennethreitz.org
License: MIT
Location: c:\users\ichiro\documents\pythonscraping\venv\lib\site-packages
Requires: parse, fake-useragent, requests, w3lib, bs4, pyppeteer, pyquery
Required-by:
プログラミング方法
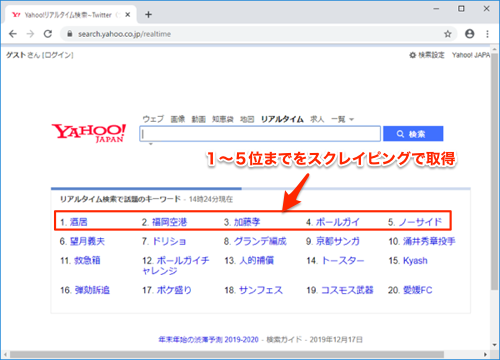
実際にrequests-htmlを用いてプログラミングしてみます。今回は以下のYahoo!リアルタイム検索 から、1〜5位までをスクレイピングで取得します。
スクレイピングする内容
コード
from requests_html import HTMLSession
url = "https://search.yahoo.co.jp/realtime"
# セッション開始
session = HTMLSession()
r = session.get(url)
# ブラウザエンジンでHTMLを生成させる
r.html.render()
# スクレイピング
ranking_rows = r.html.find("div.lst.cf")
ranking_list = []
if ranking_rows:
# 1〜5位だけを取得
ranking_top5 = ranking_rows[0].find("p.que_3")
for item in ranking_top5:
ranking_list.append(item.text[2:])
print(ranking_list)
実行すると以下のように、1〜5位がリストで出力されます。
['酒居', '福岡空港', '加藤孝', 'ボールガイ', 'ノーサイド']コードのポイントは、r.html.render()を実行しているところです。これにより、ブラウザで表示される内容を生成させています。
HTMLの構文解析は、BeautifulSoupでは以下のようにselect()メソッドを利用しましたが、requests-htmlではfind()メソッドで同様にCSSセレクタを指定して要素を検索できます。

Chromiumブラウザに関する注意点
上記でも少し触れましたが、requests-htmlはpyppeteerというライブラリにより内部でヘッドレスブラウザを起動させてスクレイピングを行います。ヘッドレスブラウザとしてオープンソースのChromiumブラウザを利用しますが、以下のようにいくつか注意点があります。
初回実行時にタイムアウトエラーになることがあります
初回実行時には、以下のようにpyppeteerライブラリがChromiumブラウザをダウンロードします。ここで以下のようにタイムアウトエラーになることがあります。
ダウンロードは初回だけで、一度済めば次回はダウンロードしませんので、ここでエラーになる場合は何度かプログラムを実行し直してみてください。
[W:pyppeteer.chromium_downloader] start chromium download.
Download may take a few minutes.
100%|██████████| 127496521/127496521 [00:15<00:00, 8063261.45it/s]
[W:pyppeteer.chromium_downloader]
chromium download done.
[W:pyppeteer.chromium_downloader] chromium extracted to: C:\Users\ichiro\AppData\Local\pyppeteer\pyppeteer\local-chromium\575458
Traceback (most recent call last):
File "C:\Users\ichiro\Documents\PythonScraping\venv\lib\site-packages\requests_html.py", line 598, in render
content, result, page = self.session.loop.run_until_complete(self._async_render(url=self.url, script=script, sleep=sleep, wait=wait, content=self.html, reload=reload, scrolldown=scrolldown, timeout=timeout, keep_page=keep_page))
File "C:\Users\ichiro\AppData\Local\Programs\Python\Python38-32\lib\asyncio\base_events.py", line 608, in run_until_complete
return future.result()
File "C:\Users\ichiro\Documents\PythonScraping\venv\lib\site-packages\requests_html.py", line 512, in _async_render
await page.goto(url, options={'timeout': int(timeout * 1000)})
File "C:\Users\ichiro\Documents\PythonScraping\venv\lib\site-packages\pyppeteer\page.py", line 862, in goto
raise error
pyppeteer.errors.TimeoutError: Navigation Timeout Exceeded: 8000 ms exceeded.
Chromiumブラウザがダウンロードできない場合(手動ダウンロードの方法)
この初回のChromiumブラウザのダウンロードがプロキシサーバーでブロックされてしまう場合は、以下の手順で手動でダウンロードします。
- 以下のアドレスからChromium(Windows32bit用)のzipファイルをダウンロードします。
- 解凍した中の「chrome-win32」フォルダを以下のフォルダにコピーします。
- 「chrome-win32」フォルダ内の
chrome.exeが以下のようなパスになっているか確認します。
https://storage.googleapis.com/chromium-browser-snapshots/Win/575458/chrome-win32.zip
C:\Users\ユーザー名\AppData\Local\pyppeteer\pyppeteer\local-chromium\575458\C:\Users\ユーザー名\AppData\Local\pyppeteer\pyppeteer\local-chromium\575458\chrome-win32\chrome.exeここで575458はChromiumのバージョンです。今回使用しているpyppeteerはversion=0.0.25ですが、今後バージョンアップに伴いChromiumが新しいバージョンに置き換えられた場合は、以下の場所にある__init__.pyファイルの中身でChromiumのバージョンを確認できます。
# Python3.7の場合
C:\Users\ユーザー名\AppData\Local\Programs\Python\Python37-32\Lib\site-packages\pyppeteer\__init__.py> py -m pip listChromiumブラウザにプロキシサーバーを指定する方法
プロキシサーバーを経由する場合は、プロキシサーバーのアドレスを以下のようにHTMLSession()に指定します。同時に、session.get()でリクエストする方にも指定しておきます。
...
# セッション開始
session = HTMLSession(browser_args=['--no-sandbox', '--proxy-server=proxy.example.co.jp:8080'])
r = session.get(url, proxies= {"http": "http://proxy.example.co.jp:8080","https": "https://proxy.example.co.jp:8080"})
...
browser_args=に、Chromiumブラウザ(chrome.exe)の起動オプションを指定できます。
どのように使い分けるか
requests-htmlは、ブラウザと同じ内容を取得でき、BeautifulSoupを呼び出さなくてもHTMLの構文解析もできます。まさにオールインワンのライブラリです。
しかし、ChromiumというChromeのベースになっているオープンソースのブラウザを内部で稼働させるので、少し動作が重いです。
そのため、普段使いとしては軽快に動作する「requests + BeautifulSoup」、それでスクレイピングできないWebページは「requests-html」と使い分けて利用するのがオススメです。