ネット通販において、有力な判断材料となるのが「レビュー」です。しかし、レビューから判断するのは、実はかなり高度な知的作業です。内容の読解力だけでなく、レビュワーの価値観などを想像する力も必要とします。だから、買い物は楽しくもあり、疲れる行為なのです。
人間が使える意思決定の総量は限りがあると言われています。出来れば買い物にかける分は省力化したいです。そこで、今回はPythonでレビューを参考にしやすくなるプログラムを作成します。
買い物時に利用できるだけでなく、WebスクレイピングのPythonプログラミングの参考としてもぜひ活用してください。
本記事の目次
作成するプログラム
今回作成するプログラムは、アマゾンの製品ページからWebスクレイピングで、トップレビュー10件を読み取り、そのレビュワーの最近のレビュー傾向を調べます。これで、レビューのバイアスの程度を推測しやすくなり、即購入か、現物を確認すべきかの判断をしやすくなります。
プログラムの実行
プログラムを実行すると、以下のように製品のURLを入力するプロンプトが表示されます。アマゾンの製品ページのアドレスを入力して、Enterを押すとスクレイピングを開始します。

スクレイピングが完了すると以下のように、「本製品の評価」に続き、「トップレビュー10件のレビュワーに関する情報」を出力します。
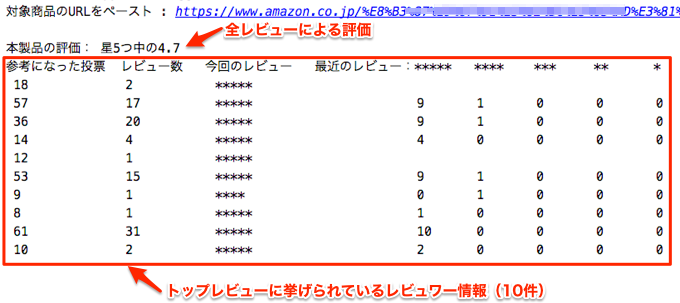
結果の見方
1行が1レビュワーのデータに相当します。例えば、以下のように9行目はトップレビューの9番目のレビュワーのデータになります。
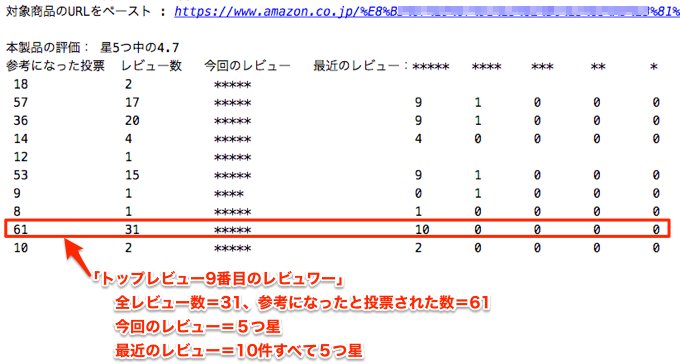
これは某書籍のデータですが、日頃からポジティブに評価するレビュワーが多く、これだけではバイアスが強いので、他のネガティブなレビューを探すか、本屋で確認するのが適当と判断されます。
なお、データの1行目と5行目の「最近のレビュー」が空欄になっているのは、レビュワーのページからレビューが取得できなかった場合です。レビューの削除等が原因と考えられます。
使用するライブラリ
Webスクレイピング定番のrequests とBeautifulSoup に加えて、requests-html とfake-useragent を利用します。
# Python Launcherを利用しない場合は、pyをpython等に置き換える
> py -m pip install requests
> py -m pip install beautifulsoup4
> py -m pip install requests-html
> py -m pip install fake-useragent
アマゾンの製品ページはrequestsで読み込めますが、各レビュワーのページはJavaScriptで動的に読み込まれるため対応できません。通常は以下のようにSeleniumでブラウザを操作します。
でも、今回は以下のページで取り上げたrequests-htmlを使用しました。これにより、Seleniumでブラウザを操作しないでも動的なページを簡単に読み込むことが可能になります。

fake-useragentは、Webページをリクエストする時に、あたかもブラウザからのように見せるために、擬似的なヘッダーを付加するのに用います。
プログラミング
requestsとBeautifulSoupを用いた典型的なコードですが、前述の通りレビュワーのページは中身がJavaScriptで動的に読み込まれるために、requests-htmlを用いています。
アマゾンのページには、主要なコンテンツの要素にdata-hook属性がよく用いられているので、CSSセレクタでこの属性を使うと要素を特定しやすくなります。CSSセレクタの使い方は以下のページを参考にしてください。
今回のプログラムの全コードは以下の通りです。
# amz_review_scraper.py
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
from requests_html import HTMLSession
from fake_useragent import UserAgent
import time
RETRY_TIMES = 3
STAR_SELECTORS = ["i.a-star-1", "i.a-star-2", "i.a-star-3", "i.a-star-4", "i.a-star-5"]
def get_with_retry(url, retry_times, codes: list):
"""requests.get()の実行(リトライ可)
"""
ua = UserAgent()
header = {'User-Agent': str(ua.chrome)}
res = requests.get(url, headers=header)
for _ in range(retry_times):
if res.status_code not in codes:
break
time.sleep(1)
res = requests.get(url, headers=header)
return res
def extract_top_reviewers(top_review_elems):
"""トップレビュワーによる評価結果とプロファイルURL
"""
lst = []
for elem in top_review_elems:
star = [i + 1 for i, ss in enumerate(STAR_SELECTORS)
if elem.select_one(ss)]
a_reviewer = elem.select_one("a.a-profile")
if star and a_reviewer:
url = urljoin(url_all_review, a_reviewer.get("href"))
lst.append((star[0], url))
return lst
def count_stars(review_elems):
"""星ごとの数をカウント
"""
counter = [0, 0, 0, 0, 0]
for elem in review_elems:
star = [i + 1 for i, ss in enumerate(STAR_SELECTORS) if elem.find(ss)]
if star:
counter[5 - star[0]] += 1
return counter
# 商品ページ
target_url = input("対象商品のURLをペースト : ")
r = get_with_retry(target_url, RETRY_TIMES, [503])
r.raise_for_status()
time.sleep(1)
# すべてのレビューページのリンク先
soup = BeautifulSoup(r.content, "html.parser")
a_all_review = soup.select_one('a[data-hook="see-all-reviews-link-foot"]')
url_all_review = urljoin(target_url, a_all_review.get("href"))
# 今回の評価
current_rating = soup.select_one('span[data-hook="rating-out-of-text"]')
# すべてのレビューページ
r = get_with_retry(url_all_review, RETRY_TIMES, [503])
r.raise_for_status()
time.sleep(1)
# トップレビュー
soup = BeautifulSoup(r.content, "html.parser")
div_top_review = soup.select('div[data-hook="review"]')
# トップレビュワー
top_reviewers = extract_top_reviewers(div_top_review)
print()
if current_rating:
print("本製品の評価:", current_rating.getText())
print("参考になった投票 レビュー数 今回のレビュー 最近のレビュー:***** **** *** ** *")
# レビュワーのページ
for current_star, reviewer_url in top_reviewers:
session = HTMLSession()
s = session.get(reviewer_url)
for i in range(RETRY_TIMES + 1):
is_last = (i == RETRY_TIMES)
s.html.render()
time.sleep(2)
stat_divs = s.html.find("div.dashboard-desktop-stat-value")
review_divs = s.html.find("div.profile-at-card")
if len(stat_divs) == 2:
stats = [s.text for s in stat_divs]
if review_divs:
# 最近のレビュー
stars = count_stars(review_divs)
print(" {:<15}{:<12}{:<27}{:<8}{:<8}{:<8}{:<8}{:<8}".format(
stats[0], stats[1], "*" * current_star,
stars[0], stars[1], stars[2], stars[3], stars[4]
))
break
elif is_last:
print(" {:<15}{:<12}{:<27}".format(
stats[0], stats[1], "*" * current_star,
))
リトライについて
「製品ページ」と「すべてのレビューのページ」では、エラーのステータスコードが503(Service Unavailable)の場合だけリトライしています。それ以外のエラーコードはリトライしても接続できないものがほとんどなので、raise_for_status()メソッドで捕獲して中断します。
「レビュワーのページ」はJavaScriptで動的に中身を読み込むため、内容が読み取れない場合は、HTMLSession.html.render()で再表示させてリトライしています。
最後に
買い物は科学です。現代では、インターネットを駆使すれば、自分にとって最良のものを、最も安い価格で手に入れることができます。
しかし、そのためにはかなりの労力が必要になってしまいます。時間はお金と同じくらい大事ですので、ぜひPythonでプログラミングすることで省力化にトライしてみてください。