今回はStable Diffusionで画像を一度に複数生成する方法をご紹介します。これで、複数の候補から気に入った画像を選べるようになります。
本サイトのStable Diffusion の記事では、これまでは一度に1つの画像を生成していました。今回の方法を使うと1つのプロンプトから違う画像を複数生成できます。また、複数のプロンプトで一斉に画像を作成することもできます。
複数の候補から選べるようになるので、気に入った画像を生成しやすくなります。
ただし、今回もGoogle Colabを利用しますが、多くの画像を生成しようとすると、どうしても無料版だとメモリが足りなくなります。そこで、今回はとりあえず複数生成の方法だけを理解するために、無料版でできる範囲で試します(それでも、割り当てが少ないときはメモリが不足することがあります)。もっと生成できる画像を増やしたい場合は、有料版の採用を検討することになります。
本記事の目次
更新履歴
[2023.01.04]アクセストークンなしでモデルにアクセスするように変更:以前はアクセストークンが必要でしたが、2022.11.28にアナウンスされた ようになくてもアクセスできるようになりました。
[2023.03.21]コード修正:以前の記事でdiffusersとtrasformersのバージョンを固定したのに伴い、コードの一部を修正しました(パイプライン実行時にautocastするようにしました)。
画像を複数生成する2つの方法
複数生成する方法は、プロンプトが「1つ」か「複数」の違いにより、以下の2通りがあります。
- 1つのプロンプトで複数の画像を生成する
- 複数のプロンプトで画像を一斉に生成する
1つ目の方法は、1つのプロンプトから異なる画像を複数生成します。2つ目の方法は、複数のプロンプトをリストで指定して、それぞれの画像を一斉に生成します。
どちらもDiffusersライブラリのパイプライン(StableDiffusionPipeline )を実行するときの設定を変えるだけで可能です。以下で実際に試してみましょう。
方法1:1つのプロンプトで複数の画像を生成する方法
以前の記事では、以下のコードを用いて1つのプロンプト(prompt)から「ゴーギャン風の富士山」を1つ生成しました。
1つのプロンプト → 1つの画像(以前の記事)
...
# プロンプト
prompt = "Mt. Fuji in the style of Gauguin"
# パイプラインの作成
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to(device)
# パイプラインの実行
generator = torch.Generator(device).manual_seed(42) # seedを前回と同じ42にする
with torch.autocast("cuda"):
image = pipe(prompt, guidance_scale=7.5, generator=generator).images[0]
...
このコードをプロンプトはこのままで2つの画像を生成するように改良してみましょう。
それには、以下のようにpipe()の引数にnum_images_per_prompt=2を追加します。また、末尾の[0]を除いて、生成された複数の画像が変数imagesに代入されるようにします。
1つのプロンプト → 2つの画像(今回)
# プロンプト
prompt = "Mt. Fuji in the style of Gauguin"
# パイプラインの作成
pipe = StableDiffusionPipeline.from_pretrained(model_id, revision="fp16", torch_dtype=torch.float16)
pipe = pipe.to(device)
# パイプラインの実行
generator = torch.Generator(device).manual_seed(42) # seedを前回と同じ42にする
with torch.autocast("cuda"):
images = pipe(prompt, guidance_scale=7.5, generator=generator, num_images_per_prompt=2).images
上記のコードを実行すると以下のように2つの異なるゴーギャン風の富士山が生成されます。

ここで、2つの画像を並べて表示するのに、torchvision というライブラリを利用しています。torchvisionを用いて画像を並べて表示する方法は以下の記事を参照してください。

なぜ2つの違う画像が生成されたのか?
ここで1つ疑問が浮かびます。なぜプロンプトが同じであり、seedも固定しているのに、違う画像が生成されるのでしょうか。それは、生成時に入力される初期のノイズが異なるからです。
StableDiffusionPipelineでは、生成する画像の個数分だけノイズをランダムに作成しておき、初期のノイズとして1つずつ入力します。そのため、一度に生成された複数の画像は、すべて異なる画像になります。ただし、後述する方法で初期のノイズを固定すれば、画像は同じになります。
方法2:複数のプロンプトで画像を一斉に生成する方法
次に複数のプロンプトを指定する方法を説明します。今回は「ゴーギャン風」と「ゴッホ風」の2つの富士山を生成するために、「Mt. Fuji in the style of Gauguin」と「Mt. Fuji in the style of Gogh」の2つのプロンプトを用意しておきます。
方法は、以下のように2つのプロンプトをリストにして、pipe()の引数に指定するだけです。pipe()の引数には「1つの文字列」だけでなく「文字列のリスト」を渡すこともができるのです。
# プロンプト
prompts = ["Mt. Fuji in the style of Gauguin",
"Mt. Fuji in the style of Gogh"]
# パイプラインの作成
pipe = StableDiffusionPipeline.from_pretrained(model_id, revision="fp16", torch_dtype=torch.float16)
pipe = pipe.to(device)
# パイプラインの実行
generator = torch.Generator(device).manual_seed(42) # seedを前回と同じ42にする
with torch.autocast("cuda"):
images = pipe(prompts, guidance_scale=7.5, generator=generator).images
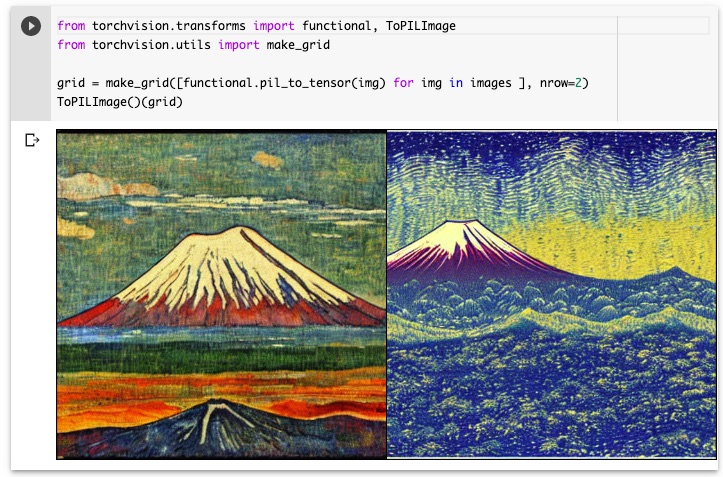
コードを実行すると以下のように「ゴーギャン風」と「ゴッホ風」の2つの富士山を生成できたのを確認できます。
初期のノイズを固定する方法
上記の2つの画像を見比べて、違和感を感じないでしょうか。
「ゴーギャン風」と「ゴッホ風」の違いはわかりますが、富士山の位置や手前の背景が異なりそもそも対象としている富士山が違うように感じると思います。この違いは、前述した初期のノイズが異なるために生じています。
そこで、ここでは初期のノイズを固定する方法を説明します。それには、以下のようにtorch.randn()で初期のノイズnoiseを自分で作成しておき、torch.cat()で2つ分の配列にして、pipe()を実行するときにキーワード引数latentsに指定します。
# プロンプト
prompts = ["Mt. Fuji in the style of Gauguin",
"Mt. Fuji in the style of Gogh"]
# パイプラインの作成
pipe = StableDiffusionPipeline.from_pretrained(model_id, revision="fp16", torch_dtype=torch.float16)
pipe = pipe.to(device)
# 初期ノイズの生成
generator = torch.Generator(device).manual_seed(42) # seedを前回と同じ42にする
h, w = 512, 512 # 生成する画像の大きさ(512pxがデフォルト)
noise_shape = (1, 4, h//8, w//8)
noise = torch.randn(noise_shape, generator=generator, device=device)
noise = torch.cat((noise, noise), 0)
# パイプラインの実行
with torch.autocast("cuda"):
images = pipe(prompts, guidance_scale=7.5, latents=noise).images
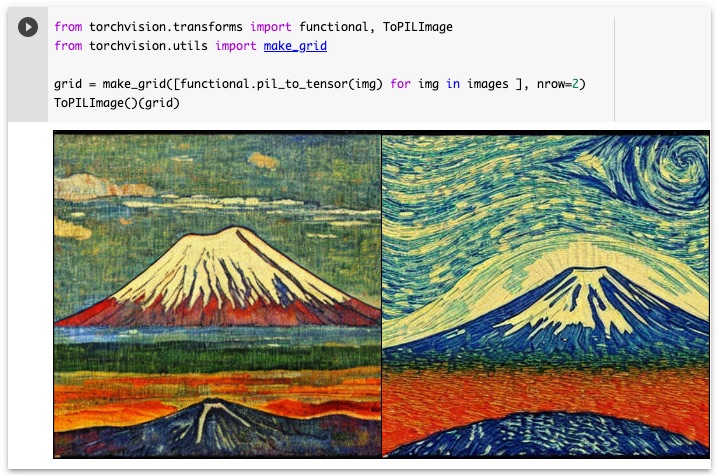
上のコードを実行すると、以下のようにゴッホ風の富士山の画像が変わったのがわかります。これであれば、2つの画像は同じ富士山を対象にしているとみることができます。
img2imgの場合
既存の画像をテキストで修正するimage-to-image(img2img)の変換でも、上記と同様に2つの方法で複数生成を実行できます。
つまり、StableDiffusionImg2ImgPipeline で作成したパイプラインを実行するときに、「num_images_per_promptを引数で指定する方法」と「複数のプロンプトをリストで指定する方法」を上記で用いた StableDiffusionPipeline と同じように使えます。
今回は画像をテキストで修正する記事で実行した以下の「ひまわりの写真をゴッホ風にする変換」を例に、複数のプロンプトを指定する方法を試してみましょう。

この変換を行うには、まずパイプラインを作成しておき、以下のようにプロンプトに1つの文字列を指定して実行しました。
プロンプトが1つの場合(前回)
# プロンプト
prompt = "the style of Gogh"
# パイプラインの実行
generator = torch.Generator(device).manual_seed(42) # 再現できるようにseedを設定
with torch.autocast("cuda"):
image = pipe(prompt, image=init_img, guidance_scale=7.5, strength=0.75, generator=generator).images[0]
...
ここのパイプラインの引数には、前述のStableDiffusionPipelineと同様に文字列のリストも指定できるようになっています。そうすると、一度に複数のプロンプトを指定した変換が可能になります。
そこで、前回の記事の「5.画像変換の実行」のコードを以下のように書き換えて実行します。pipe()の引数には、4つのプロンプトの文字列をリストにしたprompts変数を指定しています。
プロンプトが複数の場合(今回)
# プロンプト(複数)
prompts = [
"the style of Gogh", # ゴッホ風
"the style of Renoir", # ルノワール風
"the style of Monet", # モネ風
"the style of Gauguin" # ゴーギャン風
]
# パイプラインの実行
generator = torch.Generator(device).manual_seed(42) # 再現できるようにseedを設定
with torch.autocast("cuda"):
images = pipe(prompts, image=init_img, guidance_scale=7.5, strength=0.75, generator=generator).images
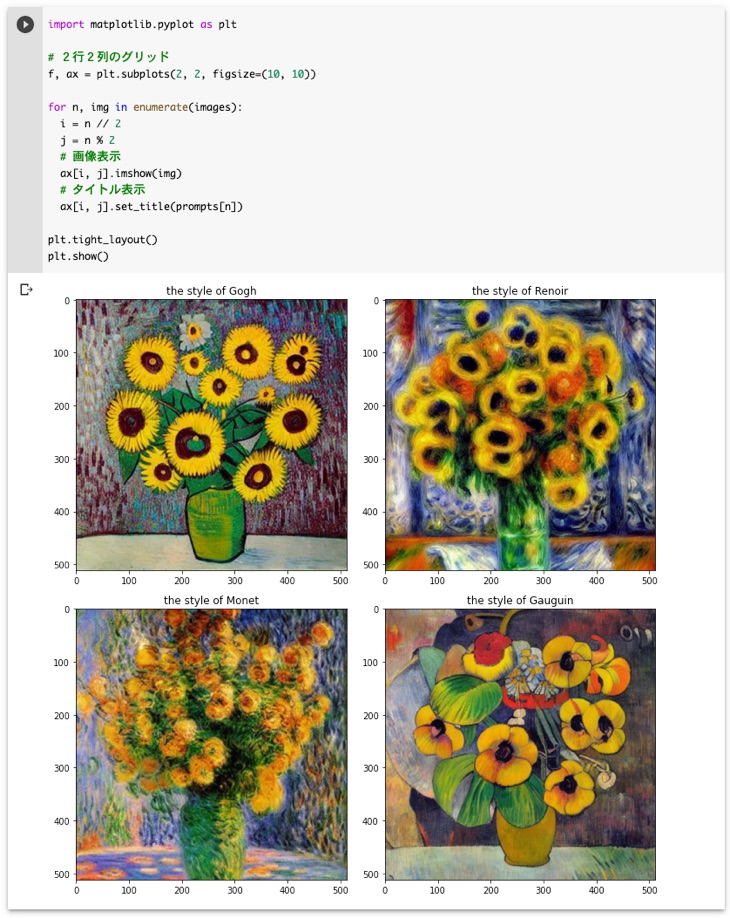
上記のコードを実行すると、以下のようにゴッホ風、ルノワール風、モネ風、ゴーギャン風に変換された4つの画像が表示されます。

タイトルを付けて表示するには
上記のコードでは、torchvisionを利用して、複数の画像を並べて表示しています。とてもシンプルなコードで表示できて便利なのですが、画像の数が増えるとタイトルを付けたい場合もでてきます。
そこで、ここではMatplotlibを用いてタイトルを付けて表示する方法をご紹介します。以下のようにグリッド(今回は2行x2列)に配置して、それぞれにset_title()でタイトルを表示します。
import matplotlib.pyplot as plt
# 2行2列のグリッド
f, ax = plt.subplots(2, 2, figsize=(10, 10))
for n, img in enumerate(images):
i = n // 2
j = n % 2
# 画像表示
ax[i, j].imshow(img)
# タイトル表示
ax[i, j].set_title(prompts[n])
plt.tight_layout()
plt.show()
上記のコードを実行すると以下のようにプロンプトをタイトルにして表示できます。
今回はmaptlotlib.pyplotのsubplotsを用いましたが、以下の記事のようにImageGridクラスを用いることもできます。