今回はStable Diffusionのモデルを利用して、「こんな風にして!」と要望をテキストで伝えるだけで既存の画像を修正(変換)する方法をご紹介します。「画像から画像」なので Image-to-Image( img2img ) と呼ばれる変換です(前回は「テキストから画像」なので txt2img)。
例えば、「ひまわりの写真」を用意して「ゴッホ風にして!」と伝えると以下のように画像を修正し変換してくれます。

今回は元になる画像に写真を使用していますが、ちゃんとした画像ではなくても大丈夫です。例えば、お絵かきのようなラフスケッチを元にして、綺麗なイラストに仕上げることも可能です。
今回は上記のゴッホ風への画像変換を、前回と同様にstable-diffusion-v1-4、さらにv2-1-baseを用いて、Diffuserライブラリで実行します。実行環境には今回も Google Colab を利用します。今回の記事のノートブックは、以下の「Open in Colab」ボタンをクリックすると開きます。
![]()
本記事の目次
更新履歴
[2022.12.11]:pipe()のキーワード引数に「init_image」が使えなくなったので「image」に変更。
[2023.01.04]アクセストークンなしでモデルにアクセスするように変更:以前はアクセストークンが必要でしたが、2022.11.28にアナウンスされた ようになくてもアクセスできるようになりました。
[2023.01.10]v2-1-baseを用いた場合も追加
[2023.03.21]ライブラリのバージョンを固定:Warning(Feature)が表示されるようになったので、diffusersとtransformersのバージョンを固定しました。影響するコードも修正しました。
コードはテキストの方を優先してください
コードはたびたび更新しています。そのため画像(Colabのスクリーンショット)の差し替えが間に合わないので、コードはテキストの方をご利用ください。
入力画像の準備
元になる入力画像を準備します。当初はフリーの素材を利用しようと思いましたが、ちょうど良い構図の写真が見つからなかったので、Stable Diffusion を用いて生成しました。

前回の方法で、stable-diffusion-v1-4を用いてプロンプトを「A photograph of a several sunflowers in vase」、seedを「84」で生成した上の写真を用います。
入力画像を Google Drive にアップロードする
今回は Google Colab で実行するので、元になる入力画像をColabから読み込めるように以下の手順で Google Drive にアップロードしておきます。
- Google Drive(drive.google.com )にログインします。
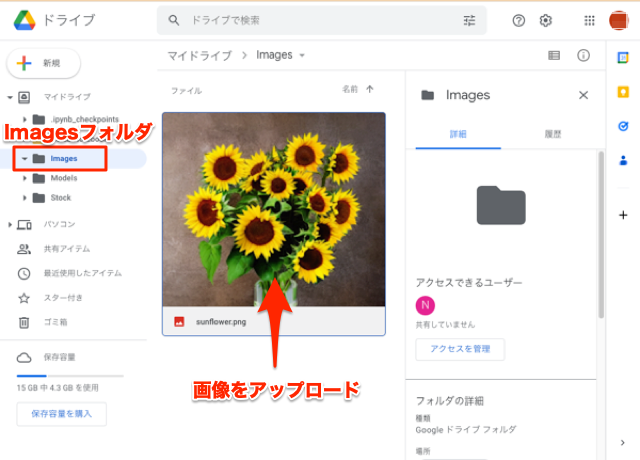
- [+新規]ボタンをクリックして、メニューから[新しいフォルダ]をクリックします。今回は「Images」というフォルダを作成します。
- Imagesフォルダにファイルをドラッグしてアップロードします。
アップロードが完了すると、以下のように入力画像(sunflower.png)が Google Drive に保存されたのを確認できます。
Google Colab + Diffusersライブラリでゴッホ風に画像変換!
これで元の画像やモデルアクセスの準備ができましたので、Goolgle Colabを利用して画像変換を実行します。
1. 新規ノートブックを作成、GPUを有効にする
前々回のときと同様に以下の手順で、Google Colab に新規ノートブックを作成します。
- Google Colab(colab.research.google.com )にログインする。
- [ファイル]-[ノートブックを新規作成]を選択します。
- ファイル名を適当な名前に変更します(今回は「sd-img2img-demo.ipynb」)。
続いて以下の手順でGPUを有効にします。
- [ランタイム]-[ランタイムのタイプを変更]を選択します。
- ダイアログが表示されるので、「ノートブックの設定」を「GPU」に変更して、[保存]をクリックします。
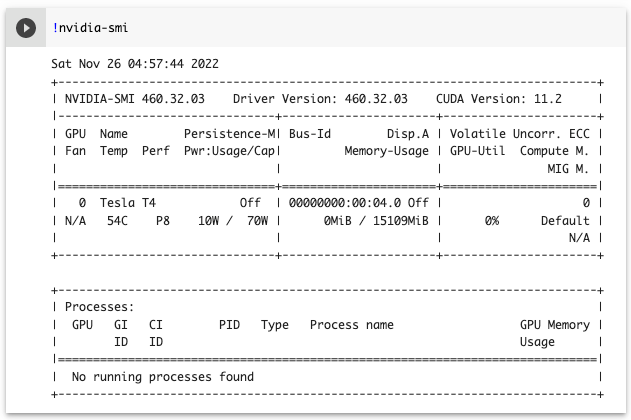
以下のコマンドを実行して、GPUが有効になっているか確認します。
!nvidia-smi以下のように表示されれば問題なくGPUが有効になっています。
2. 必要なライブラリのインストール
Diffusersライブラリなどの必要なライブラリを以下のようにpipでインストールします。
!pip install diffusers==0.12.1 transformers==4.19.2 ftfy accelerate実行すると以下のようにインストールの経過が表示されるので、完了するまでしばらく待ちます。
3. パイプラインの作成
Diffusersライブラリには以下のようなStable Diffusion用のパイプラインが用意されています。目的に応じて使い分けて、画像の生成や変換を行います。今回はImage-to-Imageの変換を行うので、以下のStableDiffusionImg2ImgPipelineを用います。
- StableDiffusionPipeline : [Text-to-Image] ← 前回使用
- StableDiffusionImg2ImgPipeline : [Image-to-Image Text-Guided] ← 今回使用
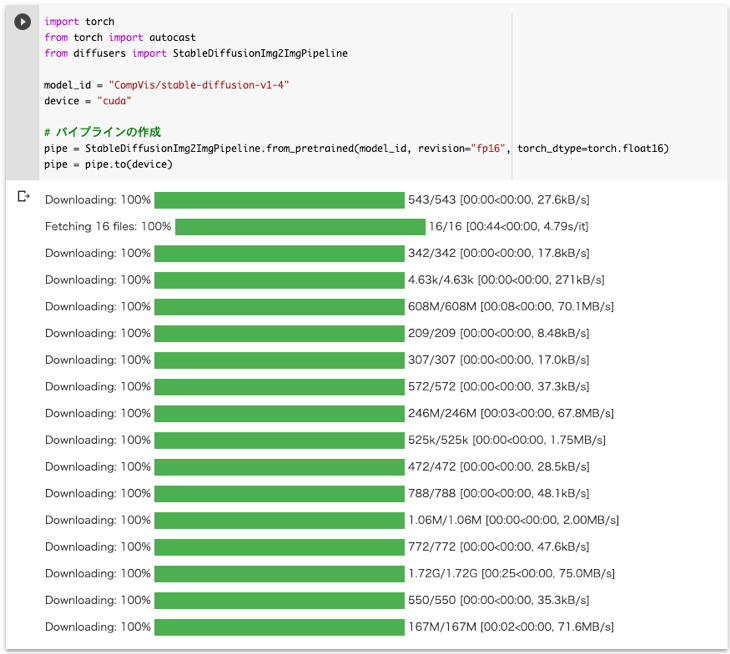
以下のコードを実行して、まずパイプラインを作成します。
import torch
from torch import autocast
from diffusers import StableDiffusionImg2ImgPipeline
model_id = "CompVis/stable-diffusion-v1-4"
device = "cuda"
# パイプラインの作成
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(model_id, revision="fp16", torch_dtype=torch.float16)
pipe = pipe.to(device)実行すると以下のように経過が表示されます。今回は約1分で完了しました。
4. 入力画像をGoogle Driveから読み込む
入力画像をパイプラインに入力できるように、以下の手順で読み込みます。
from PIL import Image
# 入力画像の読み込み(適宜自分のパスに書き換える)
init_img = Image.open("/content/drive/MyDrive/Images/sunflower.png")
init_img最後にinit_imgを呼び出しているので、以下のように読み込んだ入力画像を確認できます。

5. 画像変換の実行
これで以下のコードを実行すると画像変換できます。ここで、プロンプト(prompt)と元になる画像(init_img)をそれぞれパイプラインを実行するときの引数に設定します。プロンプトには「the style of Gogh(ゴッホ風)」を指定します。
# プロンプト
prompt = "the style of Gogh"
# パイプラインの実行
generator = torch.Generator(device).manual_seed(42) # 再現できるようにseedを設定
with torch.autocast("cuda"):
image = pipe(prompt, image=init_img, guidance_scale=7.5, strength=0.75, generator=generator).images[0]
# 変換した画像の保存
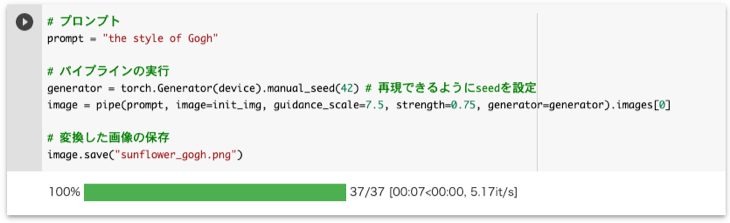
image.save("sunflower_gogh.png")実行すると以下のように経過が表示されます。今回は約20秒で完了しました。
pipe()のキーワード引数には、init_imageとimageの両方が使えていましたが、init_imageが使えなくなったのでコードを修正しました(2022.12.11)。修正前:
image = pipe(prompt, init_image=init_img,...修正後:
image = pipe(prompt, image=init_img,...
strengthパラメータについて
strengthパラメータは0.0〜1.0の値で、入力画像(元になる画像)に追加するノイズの量を制御できます。今回は0.75に設定しましたが、0.5のように小さくすると以下のように元の入力画像に近くなります。

6. 変換した画像の確認
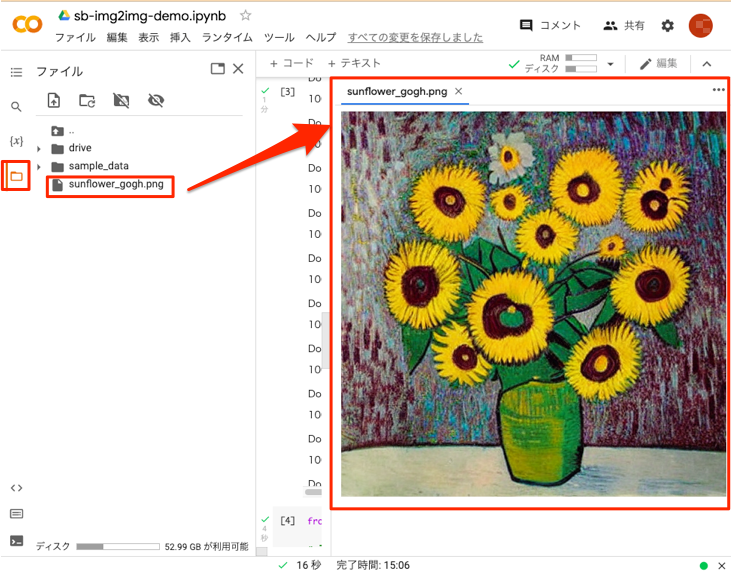
上のコードを実行するとsunflower_gogh.pngに変換した画像が保存されます。このファイルを以下のように左側で選択して表示します。このように元のひまわりの写真がゴッホ風に変換されたのが確認できます。
複数のプロンプトで一度に変換するには
今回は1つのプロンプトで変換しましたが、一度に複数のプロンプトを指定することも可能です。詳しくは以下の記事を参照してください。

v2-1-baseも試してみる!
今度はv2-1-baseのモデルを用いて変換してみましょう。
Stable Diffusion のバージョン2.1には、解像度がv1-4と同じ512×512の「v2-1-base」と768×768の「v2-1」があります。ここでは、512×512の「v2-1-base」を用います。
上のセルから続けて以下のコードを実行します。
# v2-1-baseのモデル
model_id = "stabilityai/stable-diffusion-2-1-base"
# パイプラインの作成(revisionの指定は除く)
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to(device)
# プロンプト
prompt = "the style of Gogh"
# パイプラインの実行
generator = torch.Generator(device).manual_seed(42) # 再現できるようにseedを設定
with torch.autocast("cuda"):
image = pipe(prompt, image=init_img, guidance_scale=7.5, strength=0.75, generator=generator).images[0]
# 変換した画像の保存
image.save("sunflower_gogh-v2-1-base.png")
v1-4のときは、メモリを節約するために半精度(fp16)のrevisionを使用していましたが、v2-1-baseのimg2imgはfp16に対応していないようなので、revisionの指定は除いています(つまり、デフォルトの”main”になります)。
実行すると以下のように経過が表示されます。今回は約4分で完了しました。
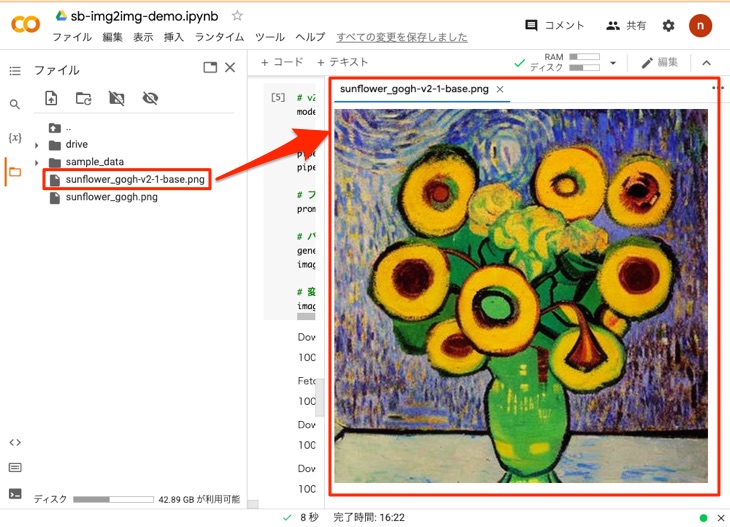
コードの実行が終了すると、変換された画像がsunflower_gogh-v2-1-base.pngに保存されるので、以下のように確認します。v1-4を用いた場合と趣きが違うゴッホ風になります。
最後に
前回までの以下の記事では「テキストから画像の画像生成(txt2img)」、今回は「画像から画像の変換(img2img)」を実行してみました。txt2imgeは「言葉」だけで画像を生成しますが、img2imgは「言葉」で「画像」をアレンジします。この2つを駆使することで、新しいアーティスティックな活動も可能になると考えています。今後もStable Diffusionから目が離せません。
前回までのtxt2imgの記事


最後に、今回のひまわりの写真を、ゴーギャン風にも変換してみましたので、以下に載せておきます。あくまでも写真をゴーギャン風に修正しただけですが、イメージはよくわかります。なお、ゴッホと共同生活をしていたゴーギャンは、ゴッホがこの世を去った後、ひまわりの絵を描きました。実際にゴーギャンが描いた肘掛け椅子に置いたひまわりは、ゴッホを思う気持ちが沁みる1枚です。
