「言葉で欲しい絵を伝えれば、AIが描いてくれる」、まさに夢のようなAIが近年注目されています。その代表的なAIの一つである「Stable Diffusion(ステーブル・ディフュージョン)」が2022年8月22日にパブリックリリース されました。たちまちすごい人気となっています。
今回はPythonユーザー向けにこの Stable Diffusion を Google Colab で体験する方法を紹介します。AI や Google Colab がはじめてでもチャレンジできるように、手順を一つひとつ丁寧に説明していますので、ぜひこの機会に体験してみてください。
AIの学習済みモデルを利用するということ
Stable Diffusion を単に体験するだけなら、Web版のデモ を利用する方法がありますが、ここではあえて自分で「学習済みモデル」をダウンロードして、コマンドで操作します。
なぜなら、この機会にAIの学習済みモデルを利用することも同時に体験するためです。
これからAI時代が本格化すれば、画像だけでなく動画、言語、コード、さらには医療のような分野まで様々な学習済みモデルが流通してくるはずです。そうなれば、優秀なモデルを自分の仕組みに取り込んで、あたかも自分にあらたな能力を付け加えるようなことが可能になります。
つまり、だれもがAIを利用してその恩恵を享受しやすくなります。今回 Stable Diffusion に触れてみるとその感覚がわかると思います。
Google Colab なら無料のGPUで体験できる
Stable Diffusion の実行には、標準で「GPU」と呼ばれるプロセッサが必要になります。一般的なPCには備わっていないので、Google Colab を利用します。Google Colab ならばGPU搭載の仮想マシンを無料で利用できます。
今回の記事の作成済みのGoogle Colabのノートブックは以下の「Open in Colab」ボタンをクリックすると開きます。
![]()
本記事の目次
- Stable Diffusionとは
- 学習済みモデルのダウンロード
- 学習済みモデルを Google Drive にアップロードする
- Google Colab でAI画像を生成!
- AIに伝えるテキスト(プロンプト)をどうやって作るのか
- 注意すること
- 最後に
もっと手軽に試すには
本記事ではすべてのプロセスを体験できる方法を紹介しているため比較的手順が多くなっています。Stable Diffusionを利用するには、もっと手順が少ないDiffusersライブラリを使う方法もあります。
更新履歴
[2023.01.03]Hugging Faceのログインに関する内容を削除:以前はモデルのファイルをダウンロードするにはHugging Faceにユーザー登録する必要がありましたが、現在ではユーザー登録しなくてもダウンロードできるようになりました。
[2023.03.20]エラー対応:エラーが発生するようになったため、必要なライブラリのインストールにおいてdiffusersとpytorch-lightningのバージョンを固定しました(「diffusers==0.12.1」「pytorch-lightning==1.9.4」)。
[2023.06.27]エラー対応:必要なライブラリのインストールにおいて、opencv-pythonのバージョンを 4.1.2.30 から 4.5.4.58 に変更しました(ColabのPythonが3.10になり、ビルド済みのファイルがレポジトリになくなったため)。
Stable Diffusionとは
「ゴーギャン風の富士山」の絵が欲しい場合、Stable Diffusion に「Mt. Fuji in the style of Gauguin」というテキストを入力すると以下のような画像を作成してくれます。当方は絵画の専門ではありませんが、まさにポール・ゴーギャン のタッチに見えます。

このように、 Stable Diffusionは、テキスト(「プロンプト」と呼ばれる)で指示するだけで描画してくれるAIです。この種類のAIは、「画像生成AI」や「描画AI」と呼ばれています。
画像生成AIでは、Stable Diffusion の他に DALL·E や Midjourney もよく知られていますが、Stable Diffusion は前述の2022年8月22日のパブリックリリースでソースやモデルが無償公開され話題を集めています。
公開の経緯などについては、チームの一員であるAI企業 Stability.AI の以下のアナウンスに記載されています。
Stable Diffusion Launch Announcement | Stability.AI
既存の画像をテキストで修正することもできる
今回のように「テキストから画像を生成する」のは、Text-to-Image(txt2img)と呼ばれます。Stable Diffusionを利用すると、さらに「テキストで既存の画像を修正する」ことも可能です。こちらは、Image-to-Image(img2img)と呼ばれ、ひまわりの写真をゴッホ風に変換するようなこともできます。
学習済みモデルのダウンロード
Stable Diffusionに関する情報は、Hugging Face社のサイト に掲載されています。このサイトはAI関連のコミュニティーになっており、Stable Diffusionのモデルは以下のミュンヘン大学のグループ「CompVis」のStable Diffusionのページで公開されています。
https://huggingface.co/CompVis/stable-diffusion
このページの「Model Access」の欄に、公開されているStable Diffusionのモデルがリストされています。各モデルは「モデルカード(Model Card)」と呼ばれるページごとに公開されています。今回は現時点で最新のstable-diffusion-v-1-4を以下のモデルカードからダウンロードします。
https://huggingface.co/CompVis/stable-diffusion-v-1-4-original
上記のリンクをクリックすると以下のようなページが表示されるので「Download the weights」にある「sd-v1-4.ckpt」をクリックしてダウンロードします。
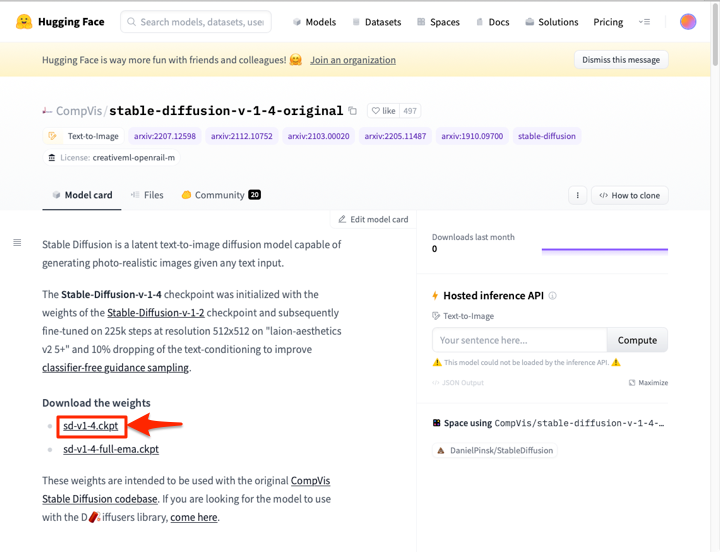
ファイルの容量は約4GBあります。ダウンロードにかかる時間は回線やサーバーの状況等により変化すると考えられますが、当方では5分程度を要しました。
なお、このファイルはcheckpointファイル(*.ckpt)と呼ばれ、重み(Weights)など学習済みモデルを再現するのに必要なデータが書き込まれています。
もうひとつの方法 ー Diffusersライブラリを利用したモデルへのアクセス
一般的にAIの学習済みモデルのファイルは、今回のように容量が大きくなります。そのため、モデルを差し替えたい場合などに、毎回ダウンロードするのは手間がかかります。
そこで、Hugging FaceではDiffusers というライブラリを提供しています。このライブラリを使うと、ダウンロードしなくても「トークン」でモデルにアクセスできます。通常はこちらの方がよく利用されますが、今回は前述の通りあえてモデルをダウンロードして使います。

学習済みモデルを Google Drive にアップロードする
学習済みのStable Diffusionモデルは、Google Colab からGoogle Drive に接続して読み込みます。そのために、学習済みモデルのファイルは同一のアカウントの Google Drive にアップロードしておきます。
そこで、先ほどダウンロードした学習済みモデルのファイル「sd-v1-4.ckpt」を Google Drive にアップロードします。手順は以下の通りです。
1.Google Drive にログイン
drive.google.com にアクセスして、Googleアカウントでログインします。
2.モデルをアップロードするフォルダを作成
Googleドライブのページが表示されたら、以下のように左上にある[+新規]ボタンをクリックして、メニューから[新しいフォルダ]をクリックします。
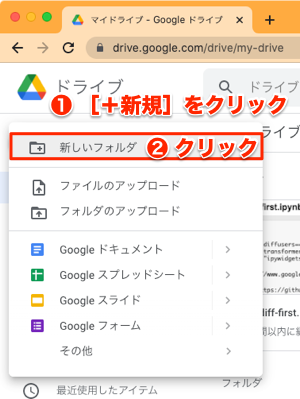
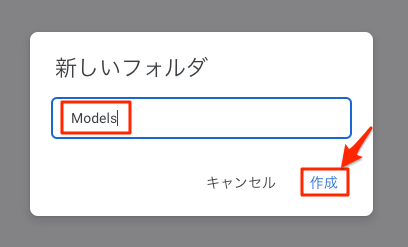
以下のようなダイアログが表示されるので、フォルダ名を入力して[作成]をクリックします。今回は「Models」というフォルダ名にしました。
3.フォルダにファイルをドラッグしてアップロード
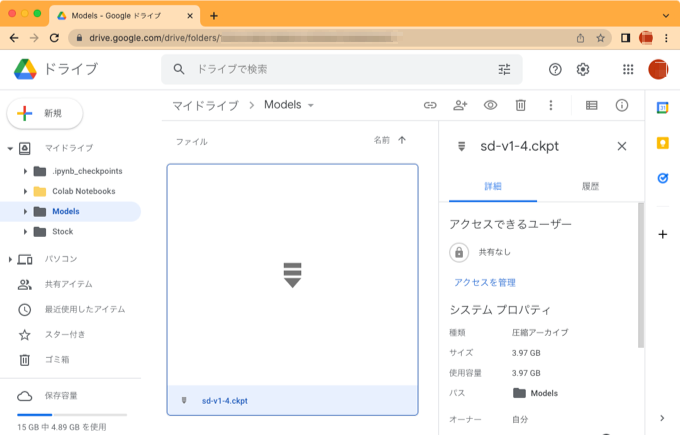
作成したフォルダを開いて、先ほどダウンロードした学習済みモデルのファイル「sd-v1-4.ckpt」をドラッグしてアップロードします。ファイルは約4GBあるので少し時間がかかります。
アップデートが完了すると以下のように「sd-v1-4.ckpt」がフォルダに保存されているのを確認できます。
Google Colab でAI画像を生成!
これで準備完了です。Google Colab を操作して Stable Diffusion で画像を生成しましょう!
まずGoogleアカウントでログインしたまま、colab.research.google.com にアクセスします。ログインしていない場合は、以下のように右上に[ログイン]ボタンが表示されるので、クリックしてログインします。
以下のようなダイアログが表示されたら、ノートブックは後でメニューから新規作成するので、ここでは[キャンセル]をクリックして閉じます。
これから Google Colab を操作してゆきますが、基本的な使い方が知りたい場合は以下の記事を参考にしてください。
なお、今回作成するノートブックは以下の「Open in Colab」ボタンをクリックすると開くことができます。左上の[ドライブにコピー]をクリックすると自分の Google Drive にコピーされます。このノートブックを使用すれば、これから説明するコマンドを入力しないで済みます。
![]()
1. Google Colab で新規ノートブックを作成
以下のように[ファイル]-[ノートブックを新規作成]を選択します。
新しいノートブックが開くので、以下のように左上のファイル名を適当な名前に変更しておきます。ここでは、「sd-demo.ipynb」にしています。
2. GPUを有効にする
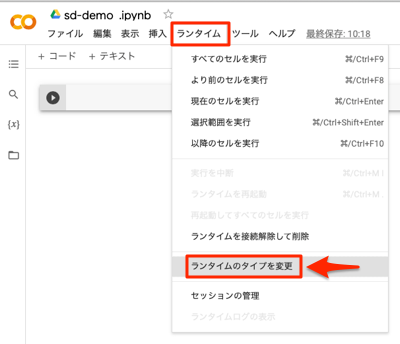
デフォルトではGPUは有効になっていないので、設定を変更します。以下のように[ランタイム]-[ランタイムのタイプを変更]を選択します。
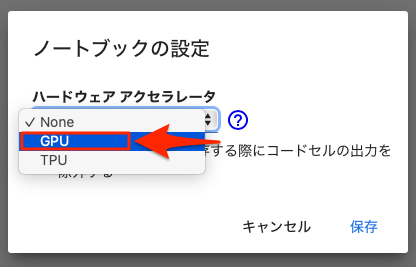
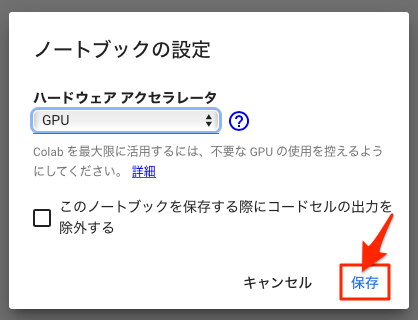
以下のようなダイアログが表示されるので、「ノートブックの設定」を「GPU」に変更して、[保存]をクリックします。
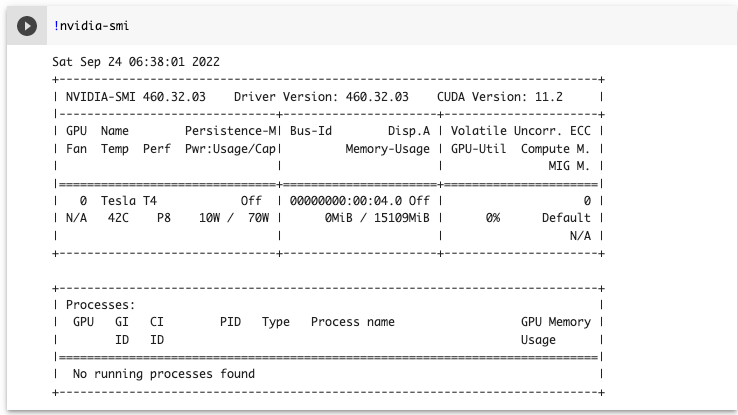
以下のコマンドを実行して、GPUが有効になっているか確認します。
!nvidia-smi以下のように表示されればOKです。「NVIDIA-SMI has failed 〜」と表示されてしまう場合はもう一度上記の設定を確認してください。
3. 必要なライブラリのインストール
Google Colab にはよく用いられるライブラリが最初からインストールされていますが、それ以外で必要となるライブラリを追加でインストールしておきます。
!pip install albumentations==0.4.3
!pip install diffusers==0.12.1
!pip install opencv-python==4.5.4.58
!pip install pudb==2019.2
!pip install imageio==2.9.0
!pip install imageio-ffmpeg==0.4.2
!pip install pytorch-lightning==1.9.4
!pip install omegaconf==2.1.1
!pip install test-tube>=0.7.5
!pip install streamlit>=0.73.1
!pip install einops==0.3.0
!pip install torch-fidelity==0.3.0
!pip install transformers==4.19.2
!pip install kornia
!pip install -e git+https://github.com/CompVis/taming-transformers.git@master#egg=taming-transformers
!pip install -e git+https://github.com/openai/CLIP.git@main#egg=clip
!pip install invisible-watermark
実行すると以下のようにインストールの経過が表示されるので、完了するまでしばらく待ちます。
以下のコマンドを実行して、念のためライブラリの依存関係をチェックします。
!pip check以下のようにjediの未インストール、tensorflowとtensorboardのバージョン不一致が指摘されますが、今回は問題ないのでこのままにしておきます。

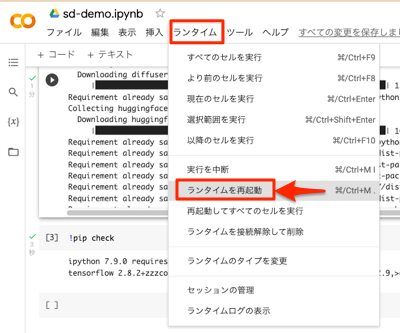
4. ランタイムを再起動
追加インストールしたライブラリのいくつかは再起動が必要なため、[ランタイム]ー[ランタイムを再起動]を選択してランタイムを再起動します。
「ランタイムを再起動してもよろしいですか?」と確認するダイアログが表示されるので、「はい」をクリックします。しばらく待つと再起動が完了します(右上のRAM/ディスクの部分の表示が切り替わります)。
5. Stable Diffusionのソースコードをダウンロード
テキストから画像を生成するスクリプトやライブラリのソースコード一式をGitHubからダウンロードします。
以下のコマンドを実行して、Stable DiffusionのソースコードをGitHubから Google Colab にダウンロードします。
!git clone https://github.com/CompVis/stable-diffusion.gitダウンロードが完了すると以下のように表示されます。
GitHubとは
GitHubはソフトウェアの共同開発に用いられるプラットフォームです。世界中のオープンソースの開発に利用されています。Stable Diffusion のソースコードもここで 管理されています。
6. Stable Diffusionのセットアップを実行
ダウンロードしたソースコードにあるセットアップを実行します。
まず、以下のコマンドを実行して、Stable Diffusion のソースコードがあるフォルダ(stable-diffusion)をカレントディレクトリにします。
%cd stable-diffusion
つぎに以下のコマンドでセットアップを実行します。
!pip install -e .終了すると以下のように最後に「Successfully installed 〜」と表示されます。
7. Google Drive をマウント
Google Drive にアップロードした学習済みモデルのファイルを読み込めるように、Google Drive をマウントします。
左端にある①フォルダのアイコンをクリックすると、以下のようなパネルが現れるので ②Google Drive のアイコンをクリックします。
以下のような確認画面が表示されるので、「Googleドライブに接続」をクリックします。
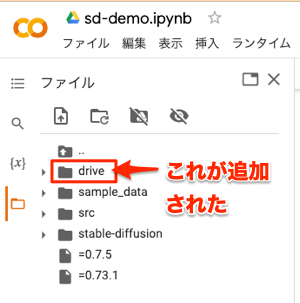
しばらく待つと以下のようにフォルダのツリー表示に「drive」が追加されます。
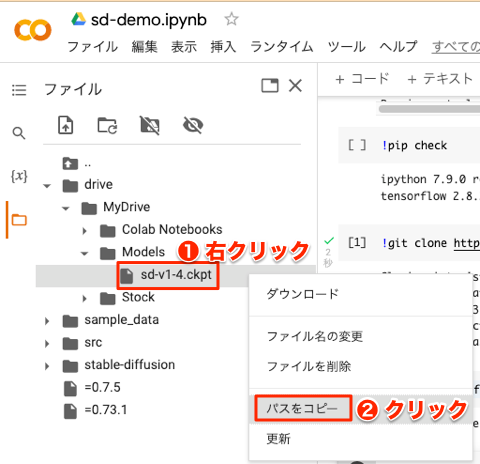
8. 学習済みモデルファイルのパスをコピー
画像生成AIを実行するときに、学習済みモデルファイルのパスが必要になります。
そこで、以下のようにフォルダのツリーを展開して「sd-v1-4.ckpt」ファイルを表示し、右クリックしてメニューから[パスをコピー]を選択します。
9. Stable Diffusion のスクリプト(txt2img.py)を実行
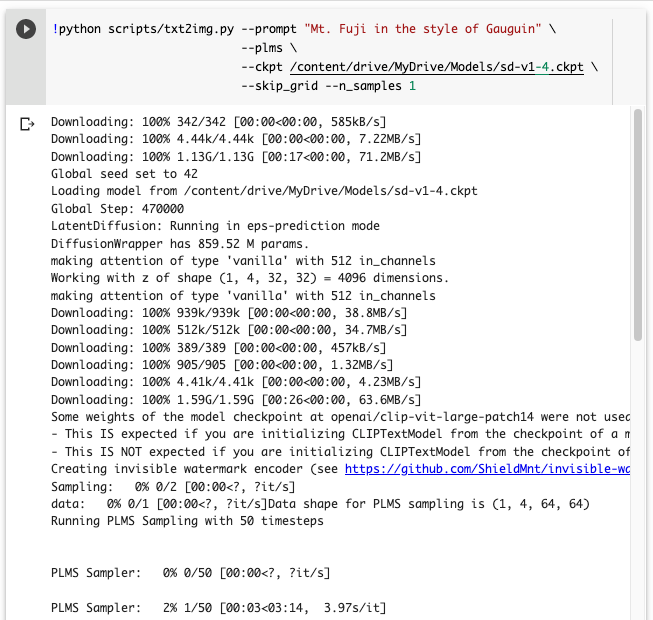
これで画像生成AIを実行する準備ができました。以下のコマンドの2箇所を自分のものに書き換えて実行します。
- 作成したい画像のテキスト:作成したい画像を英語で入力
- Google Driveにあるckptファイルのパス:前項でコピーしたパス
!python scripts/txt2img.py --prompt "作成したい画像のテキスト" --plms --ckpt Google Driveにあるckptファイルのパス --skip_grid --n_samples 1実行すると以下のように経過が表示されます(ここでは見やすくするために改行しています)。最後に「Enjoy.」と表示されたら完了です。当方では約3分で完了しました。
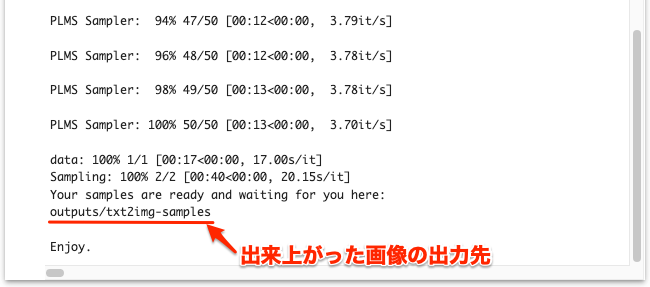
※ txt2img.py のオプションの意味は、Stable Diffusion のGitHubページ で参照できます。
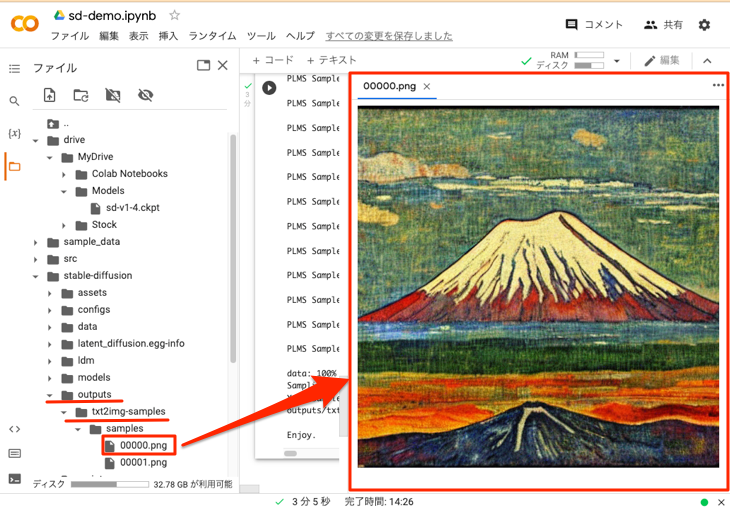
10. 生成された画像を確認
前項のコマンド実行結果の最後の方にある「画像の出力先」にある画像を確認します。今回はコマンドのオプションで--n_samples 1としているので、2つ画像が作成されます(今回は設定していませんが、--n_iterというオプションの値がデフォルトで2になっているため、「n_samples * n_iter = 2」で2つ作成されます)。
以下は1枚目の画像(stable-diffusion/outputs/txt2img-samples/samples/00000.png)をGoogle Colabでダブルクリックして表示しています。
AIに伝えるテキスト(プロンプト)をどうやって作るのか
Stable Diffusion に指示するテキストは「プロンプト(prompt)」と呼ばれます。望み通りの描画をしてもらうには、的確なプロンプトを考え出す必要があります。しかし、実はこれがなかなか奥深く、熟練を要します。それ故かプロンプトは「呪文」とも呼ばれます。
どうやってこの呪文を作るのかは、ネットで「stable diffusion prompts」や「stable diffusion writing prompts」で検索するといろんな情報が得られます。ここでは、いくつか参考になりそうな方法を挙げておきます。
まずは in the style of 〜
まずは簡単に試す方法として、今回のように「in the style of 〜」で有名な画家を指定します。するとその画風で作成してくれます。今回はゴーギャンでしたが、「ピカソ風の富士山」を指示することもできます。さらに、「A photograph of」や「An illustration of」を先頭付ければ、写真やイラストのような画像の種類も指示できます。例えば、以下のようなプロンプトが考えられます。
- Mt. Fuji in the style of Pablo Picasso
- Cute cat in the style of Rembrandt
- An illustration of Samurai in the style of Salvador Dali
Stable Diffusion Prompt Generatorを使ってみる
実際には何度もプロンプトを変えながら、欲しい画像が得られるまで試行錯誤することになると思います。とは言っても、なかなか言葉が思い浮かびません。
そんなときに便利なのが、Stable Diffusion Prompt Generator というサイトです。例えば、以下のように「可愛い猫」の画像を作りたい場合は、①「cute cat」と入力して②[送信]をクリックすると③プロンプトの候補を挙げてくれます。
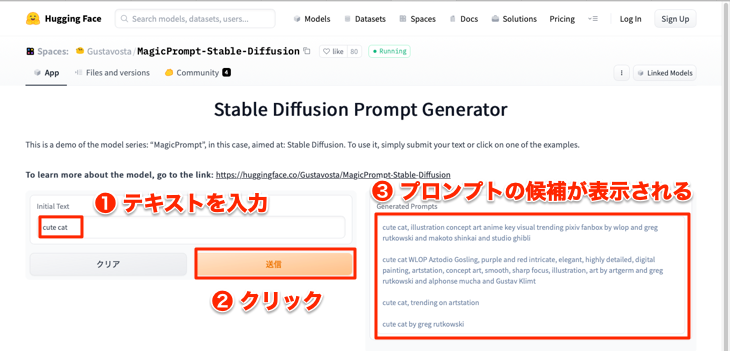
ただし、固有名称を含むプロンプトが表示される場合もあるので、よく内容を確認してから参考にする必要があります。
画集を参考にする
Stable Diffusion のようなAIを用いて作成した画像の画集が、電子書籍などで出版されはじめています。なかにはプロンプトを併記している書籍もあります。
以下の書籍は Midjourney と Stable Diffusion で作成した画像の画集です。非公開のものもありますが、プロンプトが公開されています。プロンプトだけで完全に再現することは難しいですが、画像がとても美しく、そのプロンプトと一緒に見ることができるので、とても参考になります。

注意すること
Stable Diffusion のライセンスは CreativeML Open RAIL-M です。このライセンスは以下の記事でも説明されているように、利用者が作成した画像についての責任は利用者に委ねられています。作成した画像の使用に際しては、このことをよく理解して細心の注意を払う必要があります。
Midjourneyを超えた? 無料の作画AI「 #StableDiffusion 」が「AIを民主化した」と断言できる理由 | Business Insider Japan
特に固有名称をプロンプトに含めるとはっきりとわかるように反映されるケースがあるので、公開する予定がある場合は問題になりそうな固有名称は使わないなどの対策も必要になります。
最後に
今回はStable Diffusion を体験するだけなのでシンプルなプロンプトで試しましたが、twitterの#stablediffusion を見てみるととてもプロンプトが思いつかないようなすごい画像がたくさんツィートされています。
「高性能のAIがあれば何でもできる」と一般には思われがちです。しかし、実際のところはこのプロンプト(呪文)のようにAIには「適切な指示」を与える必要があります。言い換えれば、指示の仕方がうまくなれば、AIの力を引き出せるようになります。これからは「AIをつくる」こととは別に、「AIを操る」という仕事も注目されてゆくように感じています。