VLOOKUPはビジネスで頻繁に使うエクセルの関数の一つです。この関数を使えば、他の表から行データを検索して転記できます。
例えば、以下のような社員名簿から社内資格保有者のデータを別シートに転記できます。
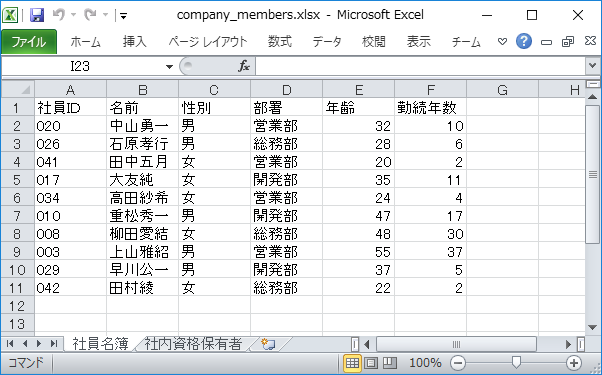
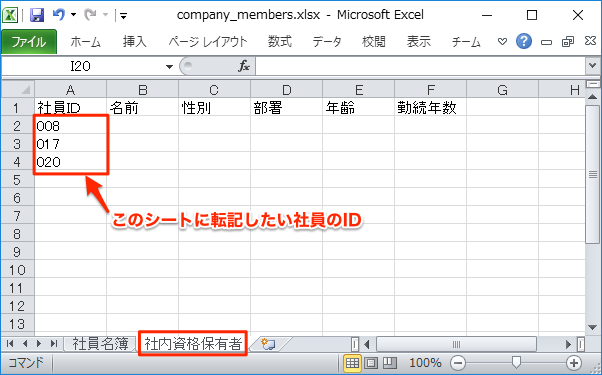
2つ目のシートには以下のように社内資格保有者の社員IDだけ入力しておきます。
VLOOKUP関数を用いれば、該当する社員データを社員名簿シートから転記できます。
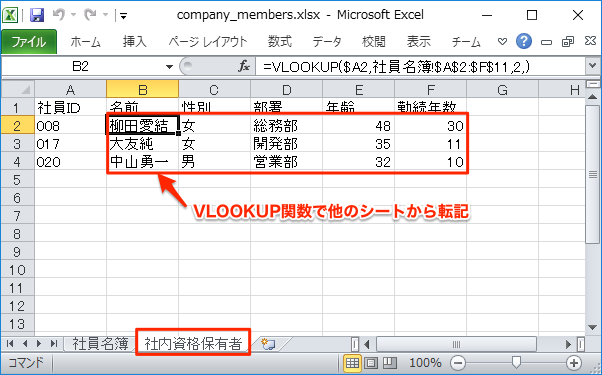
これがVLOOKUP関数の基礎的な使い方ですが、この処理はデータベース(表データ)からレコード(行データ)を検索しているに他なりません。
検索する条件は「キーが一致するかどうか」です。ここでは、”008″や”017″のような社員IDをキーにして一致する行データを検索しています。
このようなデータ検索は、普段のプログラミングでもよく行います。今回はPythonでVLOOKUP関数に相当する処理をプログラミングしてみます。
本記事の目次
エクセルデータの取り込み
社員名簿のエクセルファイルをPythonのデータとして取り込みます。エクセルファイルを読み込むには、外部ライブラリのOpenPyXL を利用します。
import openpyxl
from pprint import pprint
from operator import itemgetter
# 社員リスト
member_list = []
# エクセルファイルの取り込み
wb = openpyxl.load_workbook("./company_members.xlsx")
ws = wb["社員名簿"]
for row in ws.iter_rows(min_row=2):
values = []
for c in row:
values.append(c.value)
member_list.append(tuple(values))
# 社員IDでソート
member_list.sort(key=itemgetter(0))
pprint(member_list)
1行分のデータは{"社員ID":"026", "名前": "石原孝行", "性別": "男", ...}のように辞書として取り込むこともできますが、今回はデータを検索するだけなので、タプルで取り込みます。
company_members.xlsx(ダウンロード:company_members.zip)
上記のコードでエクセルの社員名簿を取り込むと以下のようになります。見やすくするために標準モジュールにあるpprint.pprint で表示しています。
[('003', '上山雅紹', '男', '営業部', 55, 37),
('008', '柳田愛結', '女', '総務部', 48, 30),
('010', '重松秀一', '男', '開発部', 47, 17),
('017', '大友純', '女', '開発部', 35, 11),
('020', '中山勇一', '男', '営業部', 32, 10),
('026', '石原孝行', '男', '総務部', 28, 6),
('029', '早川公一', '男', '開発部', 37, 5),
('034', '高田紗希', '女', '営業部', 24, 4),
('041', '田中五月', '女', '営業部', 20, 2),
('042', '田村綾', '女', '総務部', 22, 2)]
ここでは、operatorモジュールのitemgetterを用いて社員IDでソートしています。ソート方法の詳細は、以下のページを参考にしてください。

ソートでエラー(TypeError)になる場合
member_list.sort(key=itemgetter(0))で以下のようなエラーが発生する場合は、下の「空行」の部分まで読み込まれてしまっています(下のデータがない部分に書式設定やスペースが潜んでいるとこうなります)。
TypeError: '<' not supported between instances of 'NoneType' and 'str'その場合は、以下のようにA列(row[0])の値(value)に「None、空白文字(スペース)」のいずれかが検出されたら、行の読み込みを終了(break)するようにします。
...
for row in ws.iter_rows(min_row=2):
if not row[0].value or not str(row[0].value).strip():
break
values = []
for c in row:
values.append(c.value)
member_list.append(tuple(values))
# 社員IDでソート
member_list.sort(key=itemgetter(0))
...
ここで、このif文は以下のようにして「None」と「空白文字(スペース)」を検出します。
row[0].valueが「None」の時 :not row[0].valueは「not None = True」row[0].valueが「空白文字」の時 :str(row[0].value).strip()は「空文字」になるので、not str(row[0].value).strip()は「not “” = True」
社員IDで検索する方法
社内資格保有者のIDに一致する社員データを検索します。社員名簿のmember_listをループさせて、IDが一致する社員データだけをmastersリストに追加します。
# ...
# エクセルデータの取り込み
# 社内資格保有者の社員ID
masters_id = ["008", "017", "020"]
# 検索 -> 表示
masters = []
for member in member_list:
if member[0] in masters_id:
masters.append(member)
pprint(masters)
以下のように社内資格保有者の社員データを検索できます。
[('008', '柳田愛結', '女', '総務部', 48, 30),
('017', '大友純', '女', '開発部', 35, 11),
('020', '中山勇一', '男', '営業部', 32, 10)]
部署で検索する方法(条件に合致するデータが複数ある場合)
ひとつの「社員ID」で検索される社員は1名だけですが、開発部のような「部署」では複数の社員が検索されます。このような検索では、以下のようにリスト内包表記を使うと便利です。
# ...
# エクセルデータの取り込み
# 開発部メンバー
dep_members = [d for d in member_list if d[3] == "開発部"]
pprint(dep_members)
上のコードで、d[3]が4列目の「部署」に相当します。この列の値が”開発部”に一致する社員データを検索しています。実行すると以下のように開発部のメンバーだけを出力します。
[('010', '重松秀一', '男', '開発部', 47, 17),
('017', '大友純', '女', '開発部', 35, 11),
('029', '早川公一', '男', '開発部', 37, 5)]
なお、リスト内包表記を使わないと以下のように少し冗長になります。
# ...
# エクセルデータの取り込み
# 開発部メンバー
dep_members = []
for member in member_list:
if member[3] == "開発部":
dep_members.append(member)
pprint(dep_members)
最後に
エクセルの関数は特定の目的のために既にプログラミングされたツールです。一方、Pythonは処理を自前で組み立てるためのプログラミング言語です。
そのため、エクセルの関数についてはツールごとに使い方を覚える必要がありますが、Pythonで使うのは汎用的なプログラミングスキルのみです。だから、Pythonならば基本事項を習得すれば、広範に適用できます。
なお、他に、pandas を用いる方法もありますが、この程度の検索であれば、上記のようにシンプルなコードで実装可能です。