エクセルの表データをPythonで読み込む時は、行ごとに辞書にしておくと処理がしやすくなることがあります。例えば、以下の学生名簿で考えてみます。
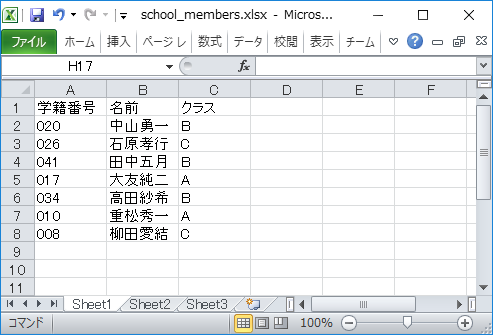
この名簿は以下のstudent_listのように1行分を学籍番号、名前、クラスをキーとする辞書にしてリストに格納できます。
>>> student_list = [
{"学籍番号": "020", "名前": "中山勇一", "クラス": "B"},
{"学籍番号": "026", "名前": "石原孝行", "クラス": "C"},
{"学籍番号": "041", "名前": "田中五月", "クラス": "B"},
{"学籍番号": "017", "名前": "大友純二", "クラス": "A"},
{"学籍番号": "034", "名前": "高田紗希", "クラス": "B"},
{"学籍番号": "010", "名前": "重松秀一", "クラス": "A"},
{"学籍番号": "008", "名前": "柳田愛結", "クラス": "C"}
]
このような「辞書のリスト」にしておけば、学籍番号などのキーで並び替えたり、学生一人ずつの個票を作成するなどの行データごと(学生ごと)の処理が容易になります。
表データの読み込みにはpandas が用いられことが多いですが、今回はOpenPyXL だけで簡単に読み取る方法をご紹介します。
本記事の目次
サンプルデータ
上記のエクセルデータをサンプルにプログラムを作成します。ファイルは以下のリンクからダウンロードできます(school_members.xlsxがzip形式で圧縮されています)。
プログラム
プログラムはエクセルデータの読み取り方の違いで、以下の2通りに作成できます。
- 1行目から順に読み取る
- 1行目と2行目以降を分けて読み取る
(1) 1行目から順に読み取る場合
まずはシンプルにws.rowsで1行目から順に読み取ると以下のようになります。
# xlsheet_read_to_dict.py
import openpyxl
# エクセルファイルの取り込み
wb = openpyxl.load_workbook("./school_members.xlsx")
ws = wb["Sheet1"]
# 学生リスト
student_list = []
# 列名のセル
header_cells = None
for row in ws.rows:
if row[0].row == 1:
# 1行目
header_cells = row
else:
# 2行目以降
row_dic = {}
# セルの値を「key-value」で登録
for k, v in zip(header_cells, row):
row_dic[k.value] = v.value
student_list.append(row_dic)
print(student_list)
1行ずつループする時に、1行目はheader_cells変数に代入しておきます。ここで、rowは「セルのタプル」なので、列名のセルがタプルで代入されます。1行目かどうかは、セル.rowで1から始める行番号が取得できるので、row[0].row == 1で判定できます。
2行目以降ではデータを辞書として登録しますが、ポイントはzip()関数を用いて、キーと値を組み合わせてループしているところです。これにより、そのまま辞書に登録できます。
ここで、k,v を出力してみると以下のように列名のセルとデータのセルがペアになっているのが確認できます。
...
print(row[0].row)
for k, v in zip(header_cells, row):
print(k, v)
...
2
<Cell 'Sheet1'.A1> <Cell 'Sheet1'.A2>
<Cell 'Sheet1'.B1> <Cell 'Sheet1'.B2>
<Cell 'Sheet1'.C1> <Cell 'Sheet1'.C2>
3
<Cell 'Sheet1'.A1> <Cell 'Sheet1'.A3>
<Cell 'Sheet1'.B1> <Cell 'Sheet1'.B3>
<Cell 'Sheet1'.C1> <Cell 'Sheet1'.C3>
4
<Cell 'Sheet1'.A1> <Cell 'Sheet1'.A4>
<Cell 'Sheet1'.B1> <Cell 'Sheet1'.B4>
<Cell 'Sheet1'.C1> <Cell 'Sheet1'.C4>
...
(2) 1行目と2行目以降を分けて読み取る場合
上記のコードでも正確に読み取りできますが、for文の中にif文があるのでブロックが二重になり、少し読みづらいです。そこで、先に1行目だけを読み取るようにプログラミングします。
# xlsheet_read_to_dict.py
import openpyxl
# エクセルファイルの取り込み
wb = openpyxl.load_workbook("./school_members.xlsx")
ws = wb["Sheet1"]
# 1行目(列名のセル)
header_cells = ws[1]
# 2行目以降(データ)
student_list = []
for row in ws.iter_rows(min_row=2):
row_dic = {}
# セルの値を「key-value」で登録
for k, v in zip(header_cells, row):
row_dic[k.value] = v.value
student_list.append(row_dic)
print(student_list)
1行目と2行目以降を分けるのに、以下のようにプログラミングしています。
- まず
ws[1]でエクセルシートの1行目のセルを取得し、 - 次に
ws.iter_rows(min_row=2)を用いて2行目からデータを読み取る
ここで、列名のある1行目だけを読み取るには、シートwsにインデックス(1から始まります)を指定すると取得できます。これは以下のようにws.rowsをリストに変換しても取得可能です。
# 1行目の取得は、以下の2つの方法どちらでも可能
header_cells = ws[1]
header_cells = list(ws.rows)[0]
読み取り結果
どちらのプログラムでも、結果は同じく以下のように出力されます。
[{'学籍番号': '020', '名前': '中山勇一', 'クラス': 'B'}, {'学籍番号': '026', '名前': '石原孝行', 'クラス': 'C'}, {'学籍番号': '041', '名前': '田中五月', 'クラス': 'B'}, {'学籍番号': '017', '名前': '大友純二', 'クラス': 'A'}, {'学籍番号': '034', '名前': '高田紗希', 'クラス': 'B'}, {'学籍番号': '010', '名前': '重松秀一', 'クラス': 'A'}, {'学籍番号': '008', '名前': '柳田愛結', 'クラス': 'C'}]
ここで pprint.pprint を用いて出力するれば、要素ごとに改行されて見やすくなりますが、辞書はソートされて{'クラス': 'B', '名前': '中山勇一', '学籍番号': '020'}のように表示されるので気をつけてください。
なお、Python3.8以降であればsort_dictsパラメータが追加されたので、pprint(student_list, sort_dicts=False)とすればソートされずに挿入した順番通りに表示できます。
特定の行または列を取得する方法
上記の方法は、つまり「エクセルの表をPythonに取り込む方法」です。1行分のデータを要素とするリストになっているので、行データを取り出すのは以下のように簡単にできます。
# 3行目のデータ
print(student_list[2]){'学籍番号': '041', '名前': '田中五月', 'クラス': 'B'}一方、1列分のデータを取り出すには、以下のようにリスト内包表記を活用します。
# 学籍番号の列のデータだけを取得
num_values = [s["学籍番号"] for s in student_list]['020', '026', '041', '017', '034', '010', '008']リスト内包表記を使わない場合は、以下のようにプログラミングできます。
num_values = []
for student in student_list:
num_values.append(student["学籍番号"])
print(n_values)