エクセルの集計でよく用いる関数と言えば、COUNTIF、AVERAGEIF、SUMIFの3つです。それぞれ条件に合うセルの個数、同じ行にある数値の合計・平均値を計算できます。
例えば、通販の顧客を都道府県ごとにカウントしたり、学校のクラスごとの平均点、支店ごとの売上合計など、活用できるシーンはたくさんあります。
今回は社員名簿のサンプルを用いて、エクセルのCOUNTIF、AVERAGEIF、SUMIFと同じ処理をPythonでプログラミングします。ポイントは、標準モジュールのitertoolsにあるgroupbyを利用するところです。
本記事の目次
エクセルのCOUNTIF、AVERAGEIF、SUMIF
今回Pythonでプログラミングするのは、以下の社員名簿を部署ごとに整理して、各部署の「人数」、「平均年齢」、「合計勤続年数」を求める処理です。
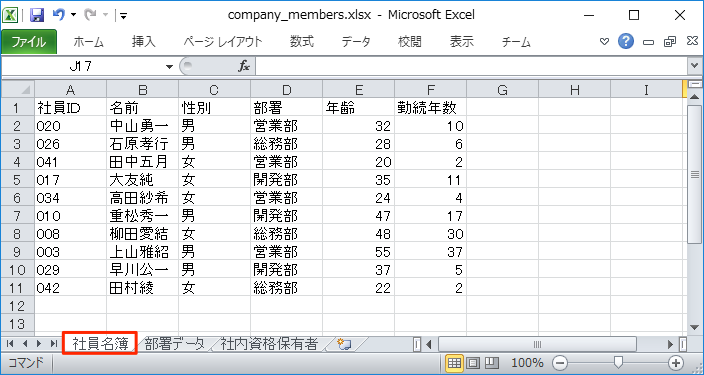
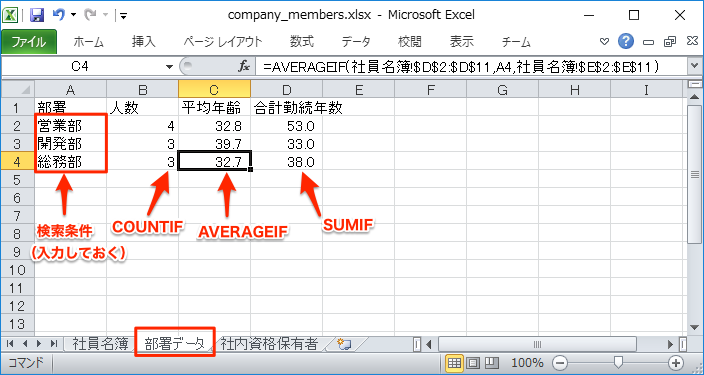
集計のための「部署データ」シートでは以下のように「部署」を検索条件にして、COUNTIF、AVERAGEIF、SUMIFで各値を求めます。
エクセルデータの取り込み
まず以下の社員名簿のエクセルファイルを読み込みまでをプログラミングします。
company_members.xlsx(ダウンロード:company_members.zip)
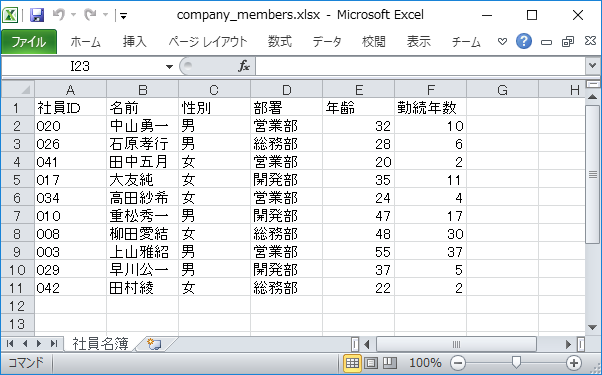
エクセルファイルの読み込みには定番のライブラリ「OpenPyXL 」を利用します。
import openpyxl
from pprint import pprint
# 社員リスト
member_list = []
# エクセルファイルの取り込み
wb = openpyxl.load_workbook("./company_members.xlsx")
ws = wb["社員名簿"]
for row in ws.iter_rows(min_row=2):
values = []
for c in row:
values.append(c.value)
member_list.append(tuple(values))
pprint(member_list)
取り込んだデータは以下のようになります。見やすくするために標準モジュールのpprint.pprint で表示しています。
[('020', '中山勇一', '男', '営業部', 32, 10),
('026', '石原孝行', '男', '総務部', 28, 6),
('041', '田中五月', '女', '営業部', 20, 2),
('017', '大友純', '女', '開発部', 35, 11),
('034', '高田紗希', '女', '営業部', 24, 4),
('010', '重松秀一', '男', '開発部', 47, 17),
('008', '柳田愛結', '女', '総務部', 48, 30),
('003', '上山雅紹', '男', '営業部', 55, 37),
('029', '早川公一', '男', '開発部', 37, 5),
('042', '田村綾', '女', '総務部', 22, 2)]
ここではタプルのリストにしましたが、辞書にしたい場合は以下のページを参考にしてください。

PythonでCOUNTIF、AVERAGEIF、SUMIFをプログラミング
COUNTIF、AVERAGEIF、SUMIFに相当する処理は、社員を部署ごとにグループ化して行います。つまり、部署ごとのグループにすれば、同じ部署の人数や年齢を集計することが可能になります。
Pythonでグループ化して処理するには、標準モジュールのitertoolsにあるgroupbyを利用します。プログラミングの方法を以下で順序立てて説明します。
1.部署でソート
まず部署でグループ化するには、部署をキーにソートしておく必要があります。
部署をキーに指定するには、list.sort()のかっこ内にkey=itemgetter(3)を入力します。社員データのタプルの部署のインデックス番号(=3)を指定します。
...
from operator import itemgetter
# 社員名簿の取り込み
...
# 部署でソート
member_list.sort(key=itemgetter(3))
pprint(member_list)
[('020', '中山勇一', '男', '営業部', 32, 10),
('041', '田中五月', '女', '営業部', 20, 2),
('034', '高田紗希', '女', '営業部', 24, 4),
('003', '上山雅紹', '男', '営業部', 55, 37),
('026', '石原孝行', '男', '総務部', 28, 6),
('008', '柳田愛結', '女', '総務部', 48, 30),
('042', '田村綾', '女', '総務部', 22, 2),
('017', '大友純', '女', '開発部', 35, 11),
('010', '重松秀一', '男', '開発部', 47, 17),
('029', '早川公一', '男', '開発部', 37, 5)]
itemgetter()を用いたソート方法の詳細は以下のページを参考にしてください。
2.部署でグループ化
ソートした社員リストをgroupby()のかっこ内に入れてループ処理すると、キー(部署)とグループ(同じ部署の社員)を返してくれます。
ここで、ソートの時と同じくkey=itemgetter(3)で部署をキーに指定します。
...
from itertools import groupby
# 社員名簿の取り込み
...
# 部署でソート
...
# 部署でグループ化
for k, g in groupby(member_list, key=itemgetter(3)):
print("部署:", k)
for m in g:
print(m)
上のコードを実行すると部署でグループ化されたのが確認できます。
部署: 営業部
('020', '中山勇一', '男', '営業部', 32, 10)
('041', '田中五月', '女', '営業部', 20, 2)
('034', '高田紗希', '女', '営業部', 24, 4)
('003', '上山雅紹', '男', '営業部', 55, 37)
部署: 総務部
('026', '石原孝行', '男', '総務部', 28, 6)
('008', '柳田愛結', '女', '総務部', 48, 30)
('042', '田村綾', '女', '総務部', 22, 2)
部署: 開発部
('017', '大友純', '女', '開発部', 35, 11)
('010', '重松秀一', '男', '開発部', 47, 17)
('029', '早川公一', '男', '開発部', 37, 5)
3.部署ごとに人数、平均年齢、合計勤続年数を計算
あとは部署ごとに人数(count)、合計年齢(sum_age)、合計勤続年数(sum_year)を集計し、平均年齢を合計年齢を人数で割って算出します。
...
# 社員名簿の取り込み
...
# 部署でソート
...
# 部署でグループ化
data_dict = {}
for k, g in groupby(member_list, key=itemgetter(3)):
# 人数,合計年齢,合計勤続年数
count, sum_age, sum_year = 0, 0, 0
for m in g:
count = count + 1
sum_age = sum_age + m[4]
sum_year = sum_year + m[5]
# 人数,平均年齢,合計勤続年数
data_dict[k] = (count, sum_age / count, sum_year)
# 出力
for k, v in data_dict.items():
print(k, "{0:2} {1:5.1f} {2:5.1f}".format(v[0], v[1], v[2]))
以下のようにエクセルの関数と同じ結果が得られます。
営業部 4 32.8 53.0
総務部 3 32.7 38.0
開発部 3 39.7 33.0
参考:pandasを用いた方法
今回の処理はpandas を利用することもできますが、単純な処理では上記のように標準モジュールだけを用いた方がわかりやすいです。特にpandasの使い方を知らなくてもすぐ処理できます。
参考までにpandasを用いたコードを掲載しておきます。
import pandas as pd
# エクセルファイルの取り込み
df = pd.read_excel("./company_members.xlsx", sheet_name="社員名簿", engine="openpyxl")
# 部署でグループ化
grouped = df.groupby("部署").agg({"社員ID": "count", "年齢": "mean", "勤続年数": "sum"})
data_columns = ["人数", "平均年齢", "合計勤続年数"]
grouped.columns = data_columns
# 結果を辞書に変換(列ではなく行ごとに変換)
data_dict = grouped.to_dict(orient='index')
# 出力
for k, v in data_dict.items():
print(k, "{0:2} {1:5.1f} {2:5.1f}".format(
v[data_columns[0]], v[data_columns[1]], v[data_columns[2]]))
出力結果は同じく以下のようになります。
営業部 4 32.8 53.0
総務部 3 32.7 38.0
開発部 3 39.7 33.0