Stable Diffusion の学習済みモデルを利用するには、次の2通りの方法があります。
- Hugging Face のモデルカードから手動でダウンロードする ← 前回はこの方法
- Hugging Face のDiffusersライブラリを使う ← 今回はこっち
前回はAIの学習済みモデルを利用する感覚をわかりやすくするために、ファイルを手動でダウンロードして使う方法を紹介しました。今回は、Diffusersライブラリ を使う方法を説明します。
この方法のメリットは、なんといっても簡単にモデルを差し替えできることです。
今後 Stable Diffusion のバージョンアップも期待される ので、そのたびに手動で毎回ダウンロードするのは結構面倒です。しかし、Diffusersライブラリを使えば、パスを書き換えるだけで簡単に新しいモデルに差し替えできます。
そこで、今回はまず前回と同じv1-4のモデルを用いて、Diffusersライブラリの使い方を説明し、その次にモデルをv1-2、v2-1-base、v2-1(解像度768×768)に差し替えて実行してみます。最後に出来上がった画像を比較します。
実行環境は、前回同様 Google Colab を利用します。今回の記事の作成済みのノートブックは以下の「Open in Colab」ボタンをクリックすると開きます。
![]()
本記事の目次
- Google Colab + DiffusersライブラリでAI画像を生成!
- モデルをv1-2に差し替えて実行!!
- モデルをv2-1-baseに差し替えて実行!!
- モデルをv2-1に差し替えて実行!!
- 最後に
更新履歴
[2023.01.04]アクセストークンなしでモデルにアクセスするように変更:以前はアクセストークンが必要でしたが、2022.11.28にアナウンスされた ようになくてもアクセスできるようになりました。
[2023.01.09]v2-1、v2-1-baseを用いた場合も追加
[2023.03.21]ライブラリのバージョンを固定:Warning(Feature)が表示されるようになったので、diffusersとtransformersのバージョンを固定しました。影響するコードも修正しました。
コードはテキストの方を優先してください
コードはたびたび更新しています。そのため画像(Colabのスクリーンショット)の更新が間に合わないので、コードはテキストの方をご利用ください。
Google Colab + DiffusersライブラリでAI画像を生成!
Google Colab で Diffusersライブラリを利用して画像を生成しますので、まず前回と同様に、Googleアカウントでcolab.research.google.com にログインします。
1. 新規ノートブックを作成、GPUを有効にする
最初に新規ノートブックを作成したら、[ランタイム]-[ランタイムのタイプを変更]を選択します。「ノートブックの設定」というダイアログが表示されるので、「GPU」を選択して[保存]をクリックしてGPUを有効にします。これらの方法は前回と同じです。
以下のコマンドを実行して、GPUが有効になっているか確認します。
!nvidia-smi以下のように表示されればOKです。「NVIDIA-SMI has failed 〜」と表示されてしまう場合はもう一度上記の設定を確認します。
2. 必要なライブラリのインストール
次にDiffusersライブラリ(diffusers )をpipを用いてインストールします。一緒に学習済みモデルの利用に必要な transformers というライブラリもインストールします。
以下のコマンドを実行してインストールします。
!pip install diffusers==0.12.1 transformers==4.19.2 ftfy accelerate実行すると以下のようにインストールの経過が表示されるので、完了するまでしばらく待ちます。
3. 画像生成を実行
これで以下のコマンドを実行すれば画像を生成できます。promptには生成したい画像のプロンプトを入力します。プロンプトは前回と同じ「Mt. Fuji in the style of Gauguin」にします。
import torch
from diffusers import StableDiffusionPipeline
model_id = "CompVis/stable-diffusion-v1-4"
device = "cuda"
# プロンプト
prompt = "Mt. Fuji in the style of Gauguin"
# パイプラインの作成
pipe = StableDiffusionPipeline.from_pretrained(model_id, revision="fp16", torch_dtype=torch.float16)
pipe = pipe.to(device)
# パイプラインの実行
generator = torch.Generator(device).manual_seed(42) # seedを前回と同じ42にする
with torch.autocast("cuda"):
image = pipe(prompt, guidance_scale=7.5, generator=generator).images[0]
# 生成した画像の保存
image.save("mt_fuji_gauguin.png")今回は無料版のGoogle Colab で実行することを想定して、半精度(fp16)用のブランチ にあるモデルを使うことで、使用するメモリ量を抑えます。そのために、パイプラインを作成するときにrevision="fp16"を指定します(デフォルトは”main”)。さらに、torch_dtype=torch.float16を渡すことで、Diffusersライブラリが半精度のモデルを期待するようにします。
なお、画像を生成するときに、seedという値が用いられますが、画像を再現するには同じ値を用いる必要があります。前回用いたtxt2img.pyではデフォルトの42を使用しているので、今回も42に設定しています。
実行すると以下のように経過が表示されます。今回は約2分で完了しました。
4. 生成された画像を確認
上のコードの最後のimage.save(ファイル名)により画像が保存されます。左側のフォルダのアイコンをクリックすると以下のようにエクスプローラーが表示されるので、画像のファイル(ここではmt_fuji_gauguin.png)をダブルクリックして画像を確認します。
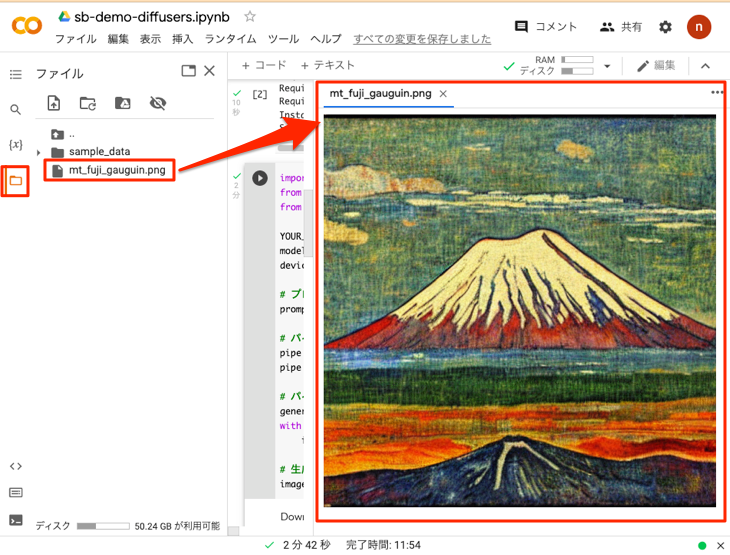
同じv1-4のモデルを用いてseedを同一にすることで前回と同じ画像が生成されました。
複数のプロンプトで一度に生成するには
今回は1つのプロンプトで生成しましたが、一度に複数のプロンプトを指定することも可能です。詳しくは以下の記事を参照してください。

モデルをv1-2に差し替えて実行!!
今度は Stable Diffusion のモデルをv1-4からv1-2に差し替えて実行してみます。
上記のセルから続けて実行するので、ここではmodel_id変数だけを書き換えます。以下のコードを実行するとv1-2モデルを用いた画像の生成が開始されます。
# v1-2のモデル
model_id = "CompVis/stable-diffusion-v1-2"
# パイプラインの作成
pipe = StableDiffusionPipeline.from_pretrained(model_id, revision="fp16", torch_dtype=torch.float16)
pipe = pipe.to(device)
# パイプラインの実行
generator = torch.Generator(device).manual_seed(42) # seedを前回と同じ42にする
with torch.autocast("cuda"):
image = pipe(prompt, guidance_scale=7.5, generator=generator).images[0]
# 生成した画像の保存
image.save("mt_fuji_gauguin_v1-2.png")実行すると以下のように経過が表示されます。今回も約2分で完了しました。
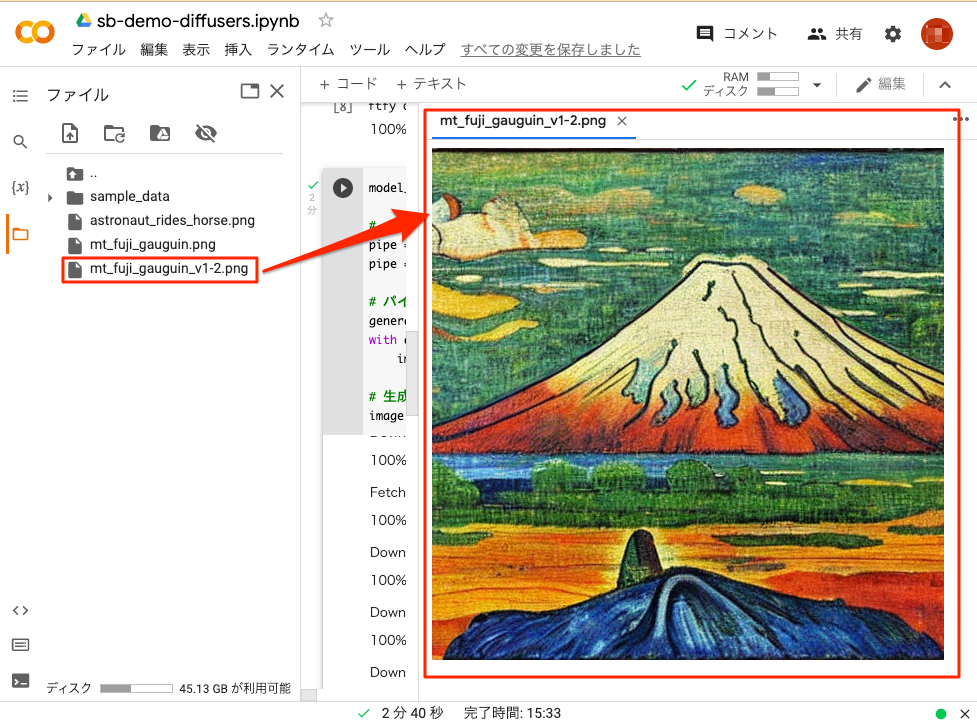
出力されたファイル(mt_fuji_gauguin_v1-2.png)を以下のように確認します。v1-4を用いた画像と少し趣きが異なる画像が生成されました。
モデルをv2-1-baseに差し替えて実行!!
今度は Stable Diffusion のモデルをv2-1-baseに差し替えて実行してみます。Stable Diffusion のバージョン2.1には、解像度が従来の512×512の「v2-1-base」と768×768の「v2-1」があります。ここでは、512×512の「v2-1-base」に差し替えます。
上記のセルから続けて実行するので、ここではmodel_id変数だけを書き換えます。以下のコードを実行するとv2-1-baseモデルを用いた画像の生成が開始されます。
# v2-1-baseのモデル
model_id = "stabilityai/stable-diffusion-2-1-base"
# パイプラインの作成
pipe = StableDiffusionPipeline.from_pretrained(model_id, revision="fp16", torch_dtype=torch.float16)
pipe = pipe.to(device)
# パイプラインの実行
generator = torch.Generator(device).manual_seed(42) # seedを前回と同じ42にする
with torch.autocast("cuda"):
image = pipe(prompt, guidance_scale=7.5, generator=generator).images[0]
# 生成した画像の保存
image.save("mt_fuji_gauguin_v2-1-base.png")
実行すると以下のように経過が表示されます。今回も約2分で完了しました。
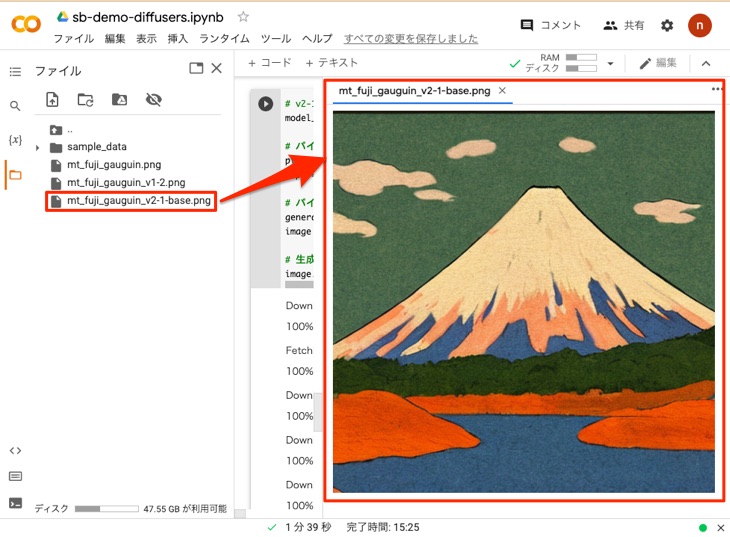
出力されたファイル(mt_fuji_gauguin_v2-1-base.png)を以下のように確認します。v1-4やv1-2を用いた画像とさらに趣きが異なる画像が生成されました。
モデルをv2-1に差し替えて実行!!
さらに、v2で新しく追加された解像度が768×768の「v2-1」についてもどのような画像が生成されるか試してみましょう。
今まで同様に上記のセルから続けて実行するので、ここではmodel_id変数だけを書き換えます。以下のコードを実行するとv2-1モデルを用いた画像の生成が開始されます。
# v2-1のモデル
model_id = "stabilityai/stable-diffusion-2-1"
# パイプラインの作成
pipe = StableDiffusionPipeline.from_pretrained(model_id, revision="fp16", torch_dtype=torch.float16)
pipe = pipe.to(device)
# パイプラインの実行
generator = torch.Generator(device).manual_seed(42) # seedを前回と同じ42にする
with torch.autocast("cuda"):
image = pipe(prompt, guidance_scale=7.5, generator=generator).images[0]
# 生成した画像の保存
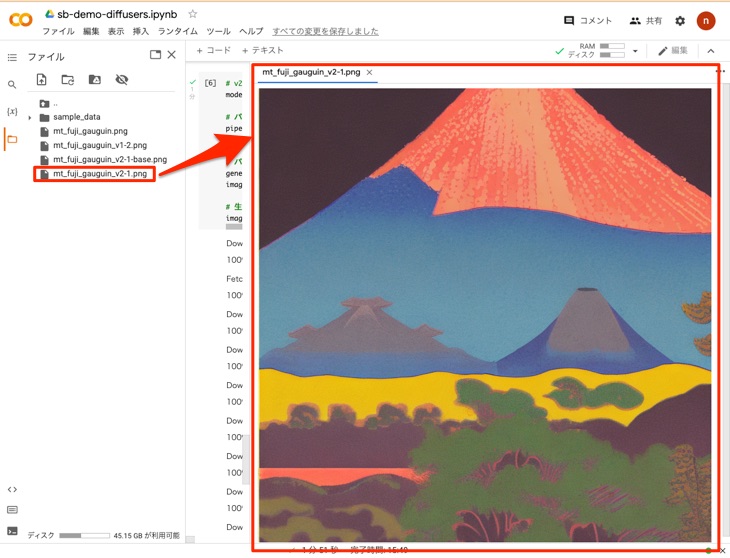
image.save("mt_fuji_gauguin_v2-1.png")
実行すると以下のように経過が表示されます。今回も約2分で完了しました。

出力されたファイル(mt_fuji_gauguin_v2-1.png)を以下のように確認します。画像のサイズが大きくなっただけでなく、かなり趣きが異なる画像が生成されました。
最後に
Diffusersライブラリを利用すると今回試したように簡単にモデルを差し替えできるようになります。今後新しいバージョンの登場も期待されるので、その時はすぐに試せて便利です。さらに、モデルのダウンロード以外にも、インストールするライブラリが少なく、モデルファイルのためのアップロードやマウントの手間もないので、かなり手順も少なくて楽です。
一方で、前回のtxt2img.pyの方は1行のコマンドで実行できるという利便性もあるので、状況に応じて前回と今回の方法を適宜使い分けるのが良いと思います。
Diffusersを使いこなすとAIアートの奥深い世界を体感できます。詳しくは以下の本がとても役立ちます。おすすめです(ただし、WebUIの解説書ではないので留意してください)。
