今回は、以下のように見開きのPDFを2ページに分割するプログラムをPythonで作成してみます。

このプログラムを使えば、A3見開きのパンフレットのPDFを2枚のA4に簡単に分割できるようになります。在宅勤務で手元にA4プリンターしかない場合にも重宝します。また、見開きでスキャンした書籍のPDFをページごとに分割するときにも使えます。
今回のプログラムでは、PDF文書をPythonで切り抜き(トリミング)する方法を用います。様々に応用できますので、ぜひ日頃のプログラミングの参考にしてください。
本記事の目次
※ 逆に2ページのPDFを1ページの見開きにする方法は以下の記事をご覧ください。

ライブラリ(PyPDF2)のインストール
今回はPDF文書のページ操作などができるライブラリ「PyPDF2 」を利用します。PyPDF2のインストールは、Windowsではコマンドプロンプトで以下のコマンドで実行できます。
> py -m pip install PyPDF2
// 環境の違いによっては以下のコマンドなどを使用
> python3 -m pip install PyPDF2
> pip intall PyPDF2
プログラムの内容
今回は以下のようにプログラム(pdf_divider.py)と同じ階層にある「samplesフォルダー」の中にある「sample_a3.pdf」を原稿として読み取り、分割したPDFを「sample_a4.pdf」に保存します。
├ samples/
│ ├ sample_a3.pdf <= 元の見開き原稿
│ └ sample_a4.pdf <= 分割したPDF(プログラムを実行すると生成される)
│
└ pdf_divider.py <= 今回のプログラム
見開きの原稿(sample_a3.pdf)は、以下のような計3ページのPDFになっているとします(総務省の業務案内パンフレット の一部を使用させていただきました)。
sample_a3.pdf(原稿)

プログラムを実行すると以下のように左右2ページに分割された計6ページになったPDFがsample_a4.pdfに保存されるようにします。
sample_a4.pdf(分割したPDF)

プログラムのコード
pdf_diveder.py
import PyPDF2
import copy
input_file = "./sample/sample_a3.pdf" # 見開き原稿
output_file = "./sample/sample_a4.pdf" # 分割したPDFの保存
pdf_reader = PyPDF2.PdfFileReader(input_file)
pdf_writer = PyPDF2.PdfFileWriter()
for i in range(pdf_reader.getNumPages()):
# 同じページのオブジェクトを2つ用意
p1 = pdf_reader.getPage(i)
p2 = copy.copy(p1)
# 原稿の左下と右上の座標を取得(用紙サイズ)
x0 = p1.mediaBox.getLowerLeft_x()
y0 = p1.mediaBox.getLowerLeft_y()
x1 = p1.mediaBox.getUpperRight_x()
y1 = p1.mediaBox.getUpperRight_y()
# 左右に分割して切り抜く領域の座標を計算
p1_lower_left = (x0, y0)
p1_upper_right = ((x0 + x1) / 2, y1)
p2_lower_left = ((x0 + x1) / 2, y0)
p2_upper_right = (x1, y1)
if abs(y1 - y0) > abs(x1 - x0):
# 縦長の場合は上下で分割するように変える
p1_upper_right = (x1, (y0 + y1) / 2)
p2_lower_left = (x0, (y0 + y1) / 2)
# 切り抜く領域(cropBox)の設定
p1.cropBox.lowerLeft = p1_lower_left
p1.cropBox.upperRight = p1_upper_right
p2.cropBox.lowerLeft = p2_lower_left
p2.cropBox.upperRight = p2_upper_right
# 縦長の場合は上,下の順に並び替える(不要な場合はこの2行は削除)
if abs(y1 - y0) > abs(x1 - x0):
p1, p2 = p2, p1
# 出力用のオブジェクトに2ページ分を追加
pdf_writer.addPage(p1)
pdf_writer.addPage(p2)
# ファイルに出力
with open(output_file, mode="wb") as f:
pdf_writer.write(f)
コードの説明
同じページのオブジェクトを2つ用意
PDFページを切り抜くには、CropBoxという「ページ境界」を設定します。ページにCropBoxを座標で指定すると、その領域の内側だけが表示・印刷されるようになります。領域の外側は削除されるのではなく表示・印刷されないようになるだけです。つまり、ファイルの容量は変わりません。
CropBoxを用いて、ページを半分ずつ分割するには、同じページのオブジェクトを2つ用意して、ページを二分するようにCropBoxの領域を半分ずつ指定します。ここがこのプログラムのポイントです。
原稿ページのオブジェクトの1つはpdf_reader.getPage(i)で用意できます。もう1つは標準モジュールの「copy 」のcopy()を用いて1つ目のp1から複製します。単にp2 = p1とするだけでは、CropBoxの座標を別々に指定しても、同じオブジェクトを参照しているので領域は同一になってしまいます。copy()でコピーを作成する必要があります。
原稿の左下と右上の座標を取得(用紙サイズ)
次に、原稿の「用紙サイズ」を把握しておきます。PDFの規格では、MediaBox, CropBox, ArtBox, TrimBox, BleedBoxの5つの「ページ境界」を指定できます。MediaBoxは必須であり「用紙サイズ」を意味します。なお、今回は使用しませんが、ArtBox, TrimBox, BleedBoxは、おもに出版物やDTPの仕上がりを指定するのに用いられます。
PDFのページ境界の種類(参照:PDF 1.7 – Adobe )
| 境界タイプ | 必須 | 用途等 |
|---|---|---|
| MediaBox | ◯ | 用紙サイズ |
| CropBox | オプション | 表示または印刷時に切り抜く領域を定義する |
| BleedBox | オプション | 出版物などの裁ち落としまでの領域を定義する |
| TrimBox | オプション | 出版物などの完成ページの領域を定義する |
| ArtBox | オプション | ページ内の内容の領域を定義する |
MediaBoxには、p1.mediaBoxでアクセスして用紙の隅の座標を取得します。PDFページの座標は「左▶右」がX+方向、「下▶上」がY+方向なので、以下のように左下と右上の座標を取得すれば、用紙サイズを把握できるようになります。各座標は、getLowerLeft_x(), getLowerLeft_y(), getUpperRight_x(), getUpperRight_y()で取得できます。

切り抜く領域の座標を計算
続いてp1とp2を切り抜くCropBoxの領域を計算します。MediaBoxと同様に「左下と右上の座標」を求めます。
ここで、原稿の配置が横長の場合は「左右」、縦長の場合は「上下」で分割するようにします。横長か縦長かは、幅(abs(x1 - x0))と高さ(abs(y1 - y0))のどちらが長いかで単純に区別します。
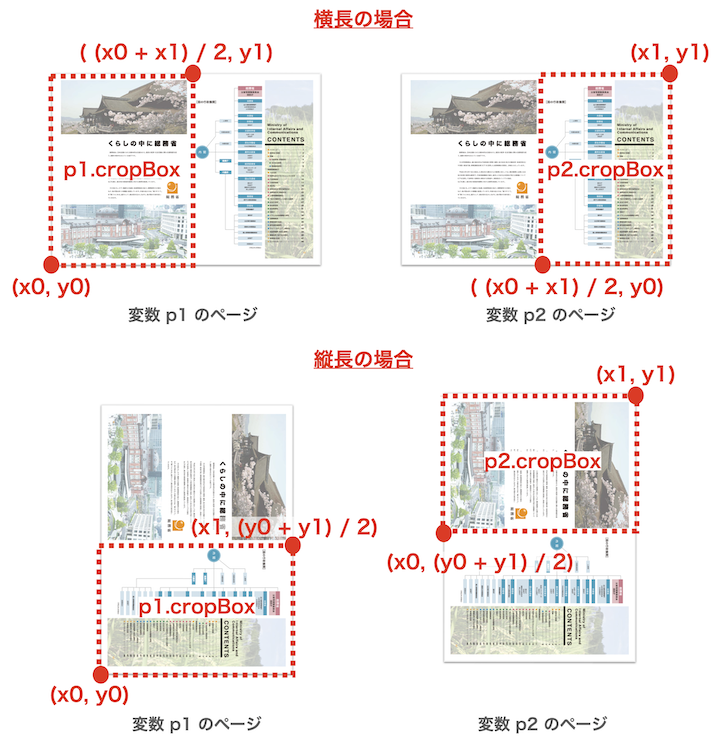
あとはこの座標をp1とp2のcropBoxに指定します。
縦長の場合は上,下の順に並び替える
縦長の原稿の場合は、分割した下半分はp1、上半分がp2になっているので、「上 ▶ 下」に並び替えることとします。このように2つの変数を入れ替えるには、p1, p2 = p2, p1だけでできます。これはタプル・スワップとも呼ばれ、以下のような簡単な例で確認できます。
>>> import datetime
>>> d1 = datetime.date(2021,1,1)
>>> d2 = datetime.date(2021,12,31)
>>> d1, d2 = d2, d1
>>> d1
datetime.date(2021, 12, 31)
>>> d2
datetime.date(2021, 1, 1)
なお、原稿によって「下 ▶ 上」のままでよい場合は、この並び替え処理は削除してください。
最後に
同じ処理はAcrobat®などでも可能ですが、プログラミングでできるようにしておくことで活用の幅が広がります。例えば、フォルダー内のすべてのPDFファイルについて実行したり、A3のページだけ処理したりできるようになります。ぜひ様々なビジネスシーンでの活用に参考にしてください。