Pythonでは、Excelファイルの入出力を外部ライブラリを用いて行います。なかでもよく用いられるのが「openpyxl」と「pandas」です。
Pythonを使い始めの頃は、「Excelファイルを扱いたいけど、どちらを使えば良いかわからない」と迷うかもしれませんが、この2つは用途がはっきりと違います。今回のこの2つのライブラリの違いと使いわけ方について、わかりやすくまとめてみましたので、ぜひ参考にしてください。
本記事の目次
- 「openpyxl」と「pandas」の違いとは
- 「帳票」を扱うなら、書式が保てる「openpyxl」
- 「データ分析」には、データ処理機能が豊富な「pandas」
- 「pandas」のデータを「openpyxl」で書き込む方法
各ライブラリのインストール方法
それぞれのライブラリのインストール方法は、以下の記事を参考にしてください。
openpyxl による Excelファイル操作方法のまとめ
NumPy、pandas、Matplotlib をpipでインストールする方法
「openpyxl」と「pandas」の違いとは
「openpyxl」と「pandas」のおもな違いをまとめると以下の表のようになります。なお、pandasはExcelファイルの他に、CSV、hdf、データベースなど様々なリソースからデータを読み込むことができますが、ここではExcelファイルのみを対象にしています。
Excelファイルを扱う上での openpyxl と pandas の違い
| openpyxl | pandas | |
|---|---|---|
| データの読み書き | ◯ | ◯ |
| 書式の読み書き | ◯ | ✕ |
| 計算・データ処理機能 | ✕ | ◎ |
| データの指定方法 | Excelと同じセル番地で指定 | 変換されたDataFrameオブジェクトの行と列で指定 |
「openpyxl」はExcelの標準規格でファイルを読み書きするためのライブラリ
拡張子が.xlsxの現在のExcelファイルは、「Office Open XML」というECMAやISO/IECで標準化された規格で作成されています。つまり、この規格に従えば、Excelファイルを読み書きできます。
「openpyxl」は、このOffice Open XMLのフォーマットでファイルを読み書きするためのライブラリです。だから、罫線、フォント、背景色などの書式も含めて、Excelファイルをそのまま読み書きできます(ただし、すべての書式などの編集まではカバーしていません)。
Excelファイルをopenpyxlで読み込むと、以下のようにブック、ワークシート、セルに対応したオブジェクトが割り当てられるので、対応するオブジェクトにアクセスして情報の読み書きを行います。

openpyxlはあくまでもExcelファイルを読み書きするライブラリなので、計算機能はありません。セルに関数を書き込むことはできますが、計算はExcelを起動しないと実行されません。
計算結果を書き込みたい場合は、自分でコーディングします。そのため、複雑な計算を行う処理では通常は「pandas」の方が便利です。
「pandas」は配列をベースとしたデータ操作・分析のためのライブラリ
「pandas」は配列をベースとした独自のデータ構造を持ちます。Excelシートは表形式のデータなので、pandasで読み込むと「DataFrame」というオブジェクトが作成され、データはその中に2次元配列として収められます。
DataFrameオブジェクトにすれば、行と列のデータをインデックスとカラム名で操作できるようになるので、非常に効率的に作業できます。さらに、多数の便利な関数やメソッドも実装されているので、データサイエンティストの手足となるパワフルなツールとして人気です。
DataFrameにどのくらいのメソッドがあるかを、以下のコードで確認すると378個もあることがわかります(属性のうち呼び出し可能なものをcallableでカウントしています)。
>>> import pandas as pd
>>> df_methods = [a for a in dir(pd.DataFrame) if callable(getattr(pd.DataFrame, a))]
>>> len(df_methods)
378
ただし、あくまでもExcelファイルから読み込むのはデータだけで書式などは引き継ぎません。「pandas」で処理したデータを、書式付きのExcelファイルに書き込みたい場合は、保存のときだけ「openpyxl」を使います。
「帳票」を扱うなら、書式が保てる「openpyxl」
「openpyxl」は、書式も含めてそのまま取り込めるので、ひな型のExcelファイルにデータを書き入れるような「帳票」の編集に使えます。実際に簡単な例でみてみましょう。
openpyxlでセルに値を書き込んでみる
以下のような請求書のひな型の「宛名」の部分に、宛名を書き入れ、別名でExcelファイルに保存するプログラムを作成してみます。
“請求書_202106.xlsx”
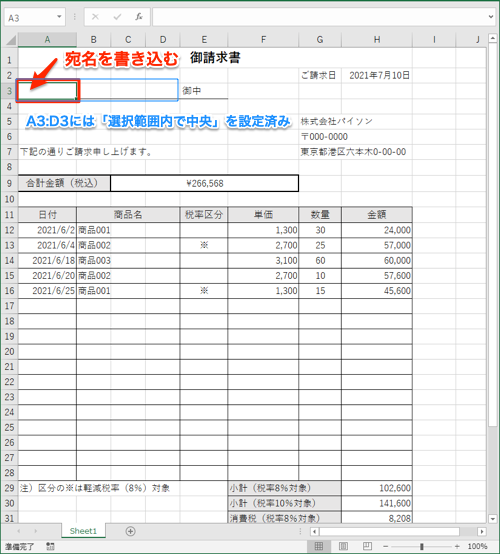
コードは以下のように、ブックとワークシートのオブジェクトをそれぞれwb、wsに作成し、ws.cell(行番号, 列番号)でA3セルにアクセスして宛名を書き込みます。最後に別名でブックを保存します。
insert_invoice_address.py
import openpyxl
# ブック、シートを開く
wb = openpyxl.load_workbook("請求書_202106.xlsx")
ws = wb["Sheet1"]
# A3セルに宛名の書き込み
ws.cell(3, 1).value = "経済産業省"
# ファイル名を指定してブックを保存
wb.save("請求書_202106_signed.xlsx")
プログラミングを実行すると以下のように宛名が書き込まれているファイルが作成されます。
請求書_202106_signed.xlsx
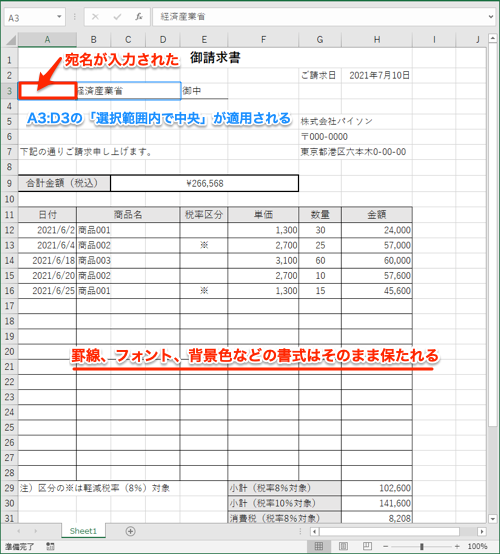
このように、Excelを使わなくてもとても簡単にExcelファイルを編集できます。
VBAも保持したままにするには
openpyxlはデフォルトでは、VBAの部分は一緒に読み込まないので、上書き保存するとなくなってしまいます。既存のファイルにあるVBAを保持したままブックを開くには、openpyxl.load_workbook(ファイル名, keep_vba=True)のようにオプションを指定して読み込みます。この方法を使えば、PDF作成などのVBAを実装したExcelファイルをひな型に使うこともできます。詳しくは以下の書籍で説明していますので、ぜひ参考にしてください。

「データ分析」には、データ処理機能が豊富な「pandas」
Pythonでデータの処理・分析を行うには、何はともあれまず「pandas」に取り込むと作業の効率がグンと良くなります。データがExcelファイルにある場合は、pandas.read_excel(ファイル名)で簡単にDataFrameオブジェクトに変換できます。
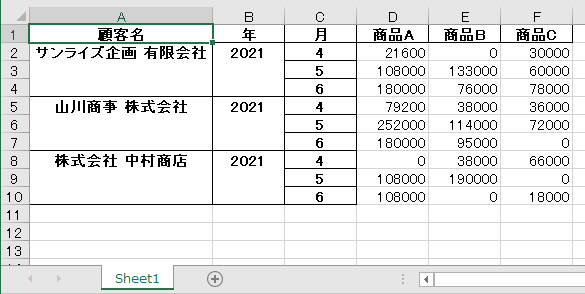
今回は以下のような「売上データ」を例にpandasの便利さを実感してみましょう。
売上データ_2021.xlsx
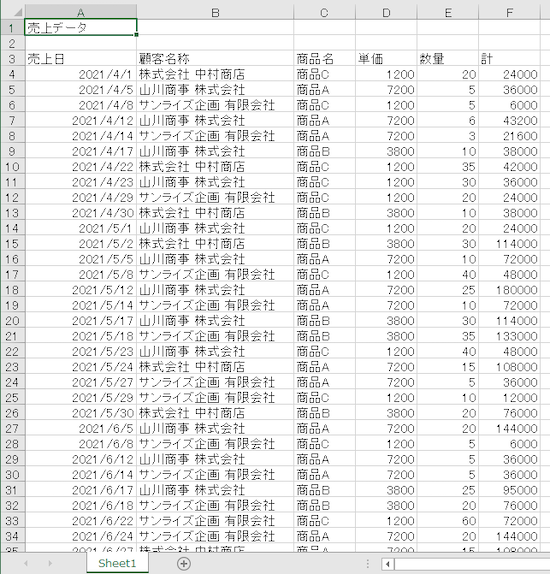
pandasでデータを検索してみる
DataFrameオブジェクト(ここでは、変数df)にデータを変換すれば、行インデックスと列ラベルでデータを検索できます。検索条件はとても柔軟に対応できるようになっています。
例えば、2021年4月のデータだけを検索するには、以下のように行インデックスに"2021-04"を指定するだけです。
>>> import pandas as pd
>>> df = pd.read_excel("売上データ_2021.xlsx", header=2, index_col="売上日", parse_dates=["売上日"])
>>> df.loc["2021-04"]
顧客名称 商品名 単価 数量 計
売上日
2021-04-01 株式会社 中村商店 商品C 1200 20 24000
2021-04-05 山川商事 株式会社 商品A 7200 5 36000
2021-04-08 サンライズ企画 有限会社 商品C 1200 5 6000
2021-04-12 山川商事 株式会社 商品A 7200 6 43200
2021-04-14 サンライズ企画 有限会社 商品A 7200 3 21600
2021-04-17 山川商事 株式会社 商品B 3800 10 38000
2021-04-22 株式会社 中村商店 商品C 1200 35 42000
2021-04-23 山川商事 株式会社 商品C 1200 30 36000
2021-04-29 サンライズ企画 有限会社 商品C 1200 20 24000
2021-04-30 株式会社 中村商店 商品B 3800 10 38000
さらに、以下のようにすれば、2021年4月の売上の合計も簡単に計算できます。
>>> df.loc["2021-04"]["計"].sum()
308800
pandasで集計をしてみる
月別の売上データを顧客名ごとに集計してみます。Excelでは、ピボットテーブルを用いて集計する作業です。pandasには同様の処理ができるpandas.pivot_table()という関数があるので、以下のようにプログラミングできます。
sales_pivot_table.py
import pandas as pd
# ブックの読み込み
df = pd.read_excel("売上データ_2021.xlsx", header=2, index_col="売上日", parse_dates=["売上日"])
# 集計(ピボットテーブル)
p_table = pd.pivot_table(df,
values="計",
index=["顧客名称", df.index.year, df.index.month],
columns=["商品名"], aggfunc="sum", fill_value=0)
# インデックス名の変更
p_table.rename_axis(["顧客名", "年", "月"], inplace=True)
# 結果をExcelファイルに保存
p_table.to_excel("売上データ_2021_集計.xlsx")
プログラムを実行すると以下のように集計したExcelファイルが作成されます。Excelを開いて自分で操作しなくても、このように一瞬で集計処理ができます。
売上データ_2021_集計.xlsx
Jupyter Notebookで使うとさらに便利!
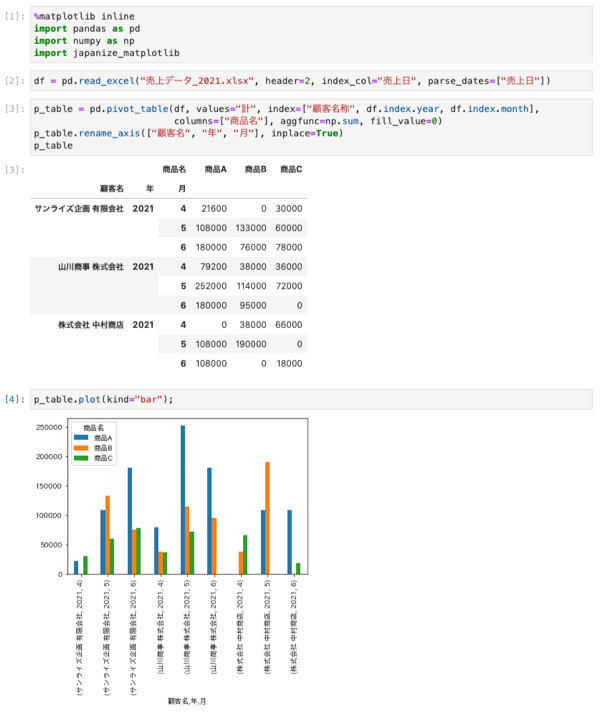
「Jupyter Notebook」でpandasを使うと、以下のようにとても見やすく出力されます。さらに、グラフもその場に表示できます。試行錯誤の経緯をそのままメモのように残せるので、データ分析では欠かせないツールです。
Jupyter Notebookの作業例(ここでは、後継のJupyterLabを使用)
Jupyter Notebookの環境を自分で準備するのは、少々面倒ですが、Google Colabであればすぐにpandasも一緒に利用できます。詳しくは以下の記事を参考にしてください。
pandasの機能をもっと知りたい場合
pandasの機能はとても膨大です。Pythonを用いたデータ分析の書籍では、ほとんどすべてpandasが利用されていますが、作者のWes McKinneyさんによる以下の書籍がとても詳しく説明してあります。是非こちらも参考にしてください。

「pandas」のデータを「openpyxl」で書き込む方法
「pandas」で分析したデータを「openpyxl」で書式付きのExcelファイルに書き込みたい場合もあります。そのときは、pandasのDataFrameのデータを、openpyxlのcellに代入します。
例えば、openpyxlで請求書の宛名を書き込んだ前述のプログラムは、宛名のデータをDataFrameにすれば、以下のようにコーディングできます。
import openpyxl
import pandas as pd
# ブック、シートを開く
wb = openpyxl.load_workbook("請求書_202106.xlsx")
ws = wb["Sheet1"]
# 宛名のデータ
data = pd.DataFrame({"Name": ["経済産業省"]})
# A3セルに宛名の書き込み
ws.cell(3, 1).value = data.iloc[0][0] # dataは1行1列のデータ
# ファイル名を指定して保存
wb.save("請求書_202106_signed2.xlsx")
また、openpyxlには、DataFrameのデータを行ごとにイテレーションするためのユーティリティーもあります。詳しくは以下の公式ドキュメントを参照してください。