ワード文書(docxファイル)は、実は「ZIP形式」で圧縮されているので、拡張子を.zipに書き換えて解凍すると埋め込まれている画像ファイルを取得できます。
手作業では結構な手間になるので、今回はPythonで自動化する方法をご紹介します。これなら、大量のワード文書から、画像を抽出することもあっという間にできます。
「文書に使用した画像ファイルを別にまとめたい」、「元の画像を紛失したので取り出したい」といった場合に、ぜひ活用してみてください。Pythonに備え付けの標準ライブラリだけでプログラミングできます!
本記事の目次
サンプルのワード文書
今回は、以下のような「ワード文書に挿入してある画像」を別ファイルに保存します。ワード文書には、ワードの[挿入タブ]▶[画像]で、PNG形式の画像を挿入しています。
sample1.docx
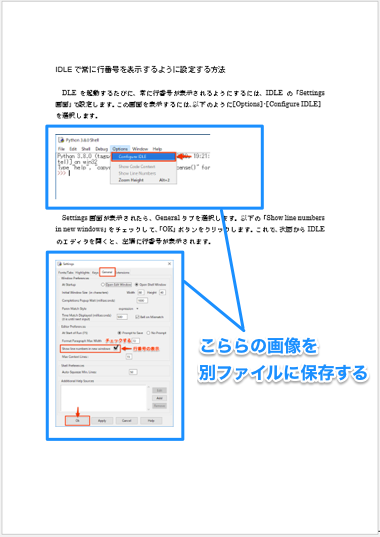
サンプルとして、同様のワード文書を全部で3つ用意して、以下のようにPythonプログラムと同じフォルダー内の「doc_files」というフォルダーに入れておきます。
├ doc_files/
│ ├ sample1.docx
│ ├ sample2.docx
│ └ sample3.docx
│
├ docx_zip_research.py
└ docx_extract_image.py <- 最終的に作成するPythonプログラム
Pythonでワード文書の中身を覗いてみる
ワード文書の中にどのようなファイル含まれるかを、Pythonの標準ライブラリの「zipfile」を利用して調べてみます。zipfileの詳細については、以下の公式ドキュメントで参照できます。
https://docs.python.org/ja/3/library/zipfile.html
ワード文書をZIP形式のファイルとして、zipfile.ZipFile()で開き、その中に含まれるファイルリストをnamelist()で取得します。ファイルリストはループで1つずつ表示して確認します。
docx_zip_research.py
import zipfile
# docxをZIP形式のファイルとして開く
docx_zip = zipfile.ZipFile("doc_files/sample1.docx")
# docxの中にあるファイル一覧を取得
zipped_files = docx_zip.namelist()
# ファイルを1つずつ表示
for file in zipped_files:
print(file)
docx_zip.close()
出力結果
[Content_Types].xml
_rels/.rels
word/document.xml
word/_rels/document.xml.rels
word/media/image1.png
word/media/image2.png
word/theme/theme1.xml
word/settings.xml
word/styles.xml
word/webSettings.xml
word/fontTable.xml
docProps/core.xml
docProps/app.xml
出力結果を見ると、ワード文書は複数のファイルで構成されているのがわかります。これらのファイルをZIP形式で1つに圧縮して、docxファイルとしています。
このリストから、sample1.docxには、image1.pngとimage2.pngの2つの画像ファイルが挿入されていることが分かります。このように画像ファイルはword/media/の中に格納されるので、以下のようにstartswith()を用いて選別できます。
docx_zip_research.py(改良)
...
# ファイルを1つずつ表示
for file in zipped_files:
# 画像ファイルだけ選別
if file.startswith("word/media/"):
print(file)
docx_zip.close()
出力結果
word/media/image1.png
word/media/image2.png
なお、画像ファイルの名前は、挿入した元のファイル名ではなく、ワード文書に埋め込まれれるとimage1.png,image2.png..のように「連番」が自動で振られます。何度か画像を差し替えたり、挿入する順番を変更して確認してみましたが、文書の上から順に付番されるようです。
Pythonでdocxから画像ファイルを取り出す方法
docxの中の画像ファイルを読み取るには、まずZIPとして開いたdocxファイルから、open()により対象の画像ファイルを開きます。例えば、docx_zip.open("word/media/image1.png")により、1つめの画像ファイルを開くことができます。
次に、開いた画像ファイルからread()を実行すると、画像のデータが読み込めるので、それをファイル名を指定して保存します。
保存する画像のファイル名は、どのワード文書から取り出したのかが分かるように、先頭に「docxファイル名_」を付けます。ここで、拡張子を除いたファイル名を取得できるstemなど、パス操作に便利な標準ライブラリの「pathlib 」を活用しています。
docx_extract_image.py
import zipfile
from pathlib import Path
docx_path = Path("doc_files/sample1.docx")
docx_zip = zipfile.ZipFile(docx_path)
zipped_files = docx_zip.namelist()
# 画像を保存するフォルダー
img_dir = Path("doc_images")
img_dir.mkdir(exist_ok=True)
for file in zipped_files:
if file.startswith("word/media/"):
# 画像ファイルを開く
img_file = docx_zip.open(file)
# 画像ファイルの読み込み
img_bytes = img_file.read()
# 保存する画像ファイル名には、「docxファイル名_」を先頭に付ける
img_path = img_dir / (docx_path.stem + "_" + Path(file).name)
# 画像ファイルの保存
with img_path.open(mode="wb") as f:
f.write(img_bytes)
img_file.close()
docx_zip.close()
画像ファイルは「doc_images」というフォルダーを作成して保存します。上記のPythonプログラム実行すると、以下のように画像ファイルが保存されます。
出力結果
├ doc_files/
│ ├ sample1.docx
│ ├ sample2.docx
│ └ sample3.docx
│
├ doc_images/
│ ├ sample1_image1.png
│ └ sample1_image2.png
│
└ docx_extract_image.py
sample1_image1.png
sample1_image2.png
なぜZIPファイルを展開しないで取り出せるのか?
zipfileライブラリには、extract()というZIPを「展開」するメソッドもあります。このメソッドを用いて、作業フォルダーに展開してから、画像ファイルをコピーすることもできます。しかし、今回のように、画像ファイルだけを別名保存する場合は、read()で読み込んでからファイル保存する方が簡単です。このようにzipfileライブラリを使うと、展開しないでもZIPの中のファイルを読み取ることができます。
複数のdocxファイルから自動で画像ファイルを取り出してみる
複数のdocxファイルから、自動で画像ファイルを取り出せるように、もう少しコードを改良します。以下のように関数にして、「doc_files」フォルダー内にあるすべてのdocxファイルから画像ファイルを抽出して保存します。
docx_extract_image.py(最終版)
import zipfile
from pathlib import Path
# ワード文書内の画像ファイルを保存する関数
def save_docx_image(docx_path, save_dir):
docx_zip = zipfile.ZipFile(docx_path)
zipped_files = docx_zip.namelist()
for file in zipped_files:
if file.startswith("word/media/"):
img_file = docx_zip.open(file)
img_bytes = img_file.read()
img_path = save_dir / (docx_path.stem + "_" + Path(file).name)
with img_path.open(mode="wb") as f:
f.write(img_bytes)
img_file.close()
docx_zip.close()
doc_dir = Path("doc_files")
img_dir = Path("doc_images")
img_dir.mkdir(exist_ok=True)
# doc_filesフォルダー内のdocxファイルを検索
for docx in doc_dir.glob("*.docx"):
save_docx_image(docx, img_dir)
実行すると、今回は1つのワード文書に2つ画像が挿入されているので、以下のように合計6つの画像ファイルを取り出して保存できたのが確認できます。
出力結果
├ doc_files/
│ ├ sample1.docx
│ ├ sample2.docx
│ └ sample3.docx
│
├ doc_images/
│ ├ sample1_image1.png
│ ├ sample1_image2.png
│ ├ sample2_image1.png
│ ├ sample2_image2.png
│ ├ sample3_image1.png
│ └ sample3_image2.png
│
└ docx_extract_image.py