最近のモダンなブラウザには、開発者向けのツールが付属しています。このツールを使えば、ブラウザに表示されているHTML要素の内容や属性を簡単に調べることができます。
このツールは、Webスクレイピングで「どのようなCSSセレクタを指定すれば要素を取得できるか」を検討するのにとても重宝します。今回はGoogle Chromeを例に使い方を説明します。
ツールの開き方
調べたい要素で右クリックして、メニューから検証を選択します。
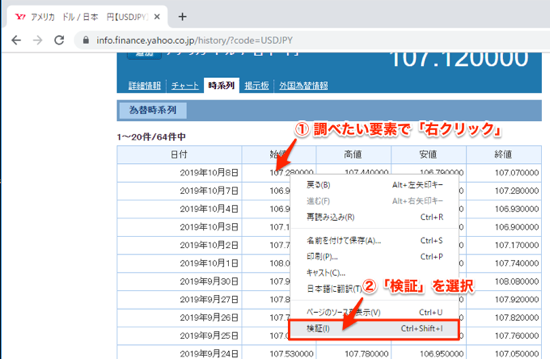
するとChromeの開発者ツールが開き、以下のように選択した要素がハイライトされます。これにより、要素がある階層や属性を調べることができます。
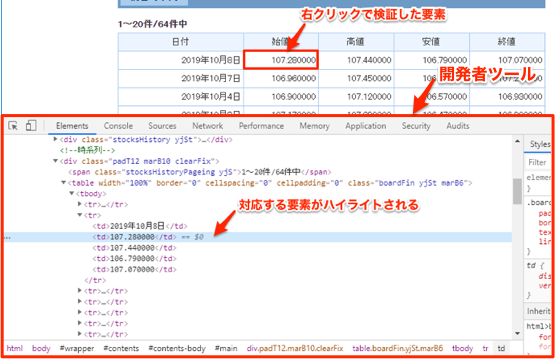
CSSセレクタのコピー
対象の要素のCSSセレクタをコピーするには、以下のように右クリック ▶ Copy ▶ Copy selectorを選択します。
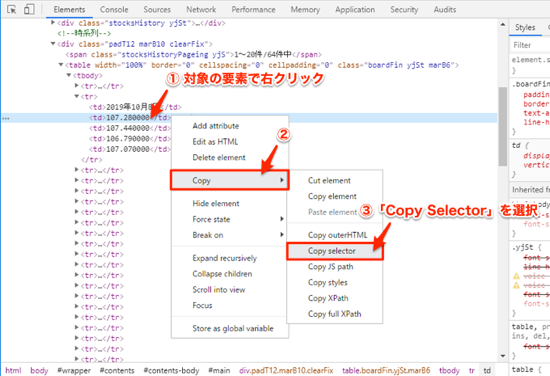
するとクリップボードに以下のようなCSSセレクタがコピーされます。
#main > div.padT12.marB10.clearFix > table > tbody > tr:nth-child(2) > td:nth-child(2)CSSセレクタの検証
上記でコピーしたCSSセレクタのdiv要素のclass属性は「padT12=padding-top:12px;」「marB10=margin-bottom:10px;」のような意味合いが推測され、デザインのために使用されていると考えられます。
つまり、現時点では要素を特定できますが、デザインが変更されれば変わってしまう可能性があります。そこで、他のCSSセレクタを検討します。
今回は以下のtable要素のclass属性のboardFinを候補として検証してみます。
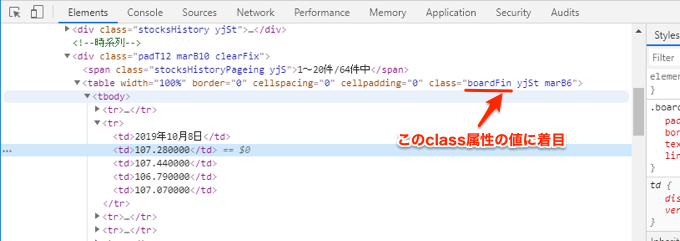
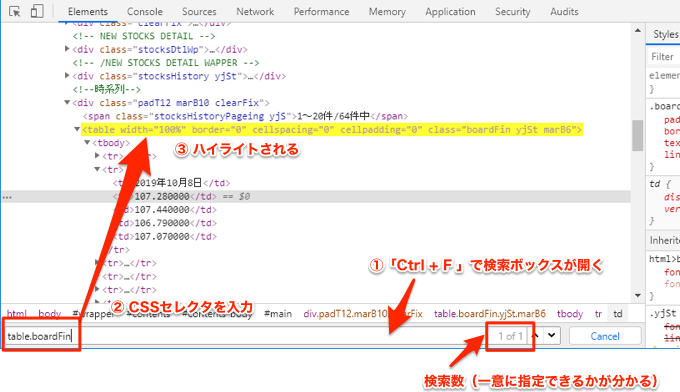
Ctrl + F で検索ボックスが表示されるので、そこにCSSセレクタを入力します。
すると以下のように、table要素がハイライトされ、さらに検索数が1つだけなので、一意に指定できることが分かります。
後は、table.boardFin trのようなCSSセレクタでざっくりと取り出して、それから以下のようにコードで処理すれば、Webスクレイピングをプログラミングできます。
# web_scraping_sample.py
import requests
from bs4 import BeautifulSoup
url = "https://info.finance.yahoo.co.jp/history/?code=USDJPY"
r = requests.get(url)
soup = BeautifulSoup(r.content, "html.parser")
row_elems = soup.select("table.boardFin tr")
data_list = []
for row_elem in row_elems:
tds = row_elem.select("td")
data_list.append([d.getText() for d in tds])
print(data_list[1:])
上記のコードを実行すると以下のようにtable要素の中身を取得できます。
[['2019年10月8日', '107.280000', '107.440000', '106.790000', '107.070000'], ['2019年10月7日', '106.960000', '107.450000', '106.550000', '107.280000'], ...]