openpyxlモジュールを用いて、ワークシートの特定のセル範囲のデータを読み取るには、範囲の「左上と右下のセル番号」を指定します。
例えば、以下のようは「C2:H12の範囲」を1行ずつ読み取るには、シートの変数がwsならばws["C2:H12"]を for文でループすれば簡単に処理できます。
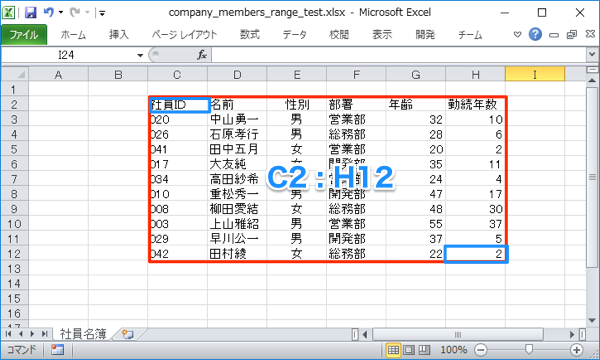
単に読み取って表示するだけなら、Pythonのコードは以下のようになります。
# xlrange-iter.py
import openpyxl
wb = openpyxl.load_workbook("company_members_range_test.xlsx")
ws = wb.worksheets[0]
for row in ws["C2:H12"]:
values = []
for col in row:
values.append(col.value)
print(values)
# 出力結果['社員ID', '名前', '性別', '部署', '年齢', '勤続年数'] ['020', '中山勇一', '男', '営業部', 32, 10] ['026', '石原孝行', '男', '総務部', 28, 6] (中略) ['029', '早川公一', '男', '開発部', 37, 5] ['042', '田村綾', '女', '総務部', 22, 2]
すべてのファイルが「C2:H12」にデータがあれば、このコードでも対応できますが、ファイルごとにデータ範囲が変わる場合にはプログラミングで何らかの工夫が必要です。
最も分かりやすい方法は、iter_rows()を用いて上から1行ずつデータを吟味しながら処理する方法です。今回は、そのような方法を様々なパターンを例にご紹介します。
本記事の目次
- 先頭カラムが空欄でない行だけ読み取る
- 空欄のセルがある行は読み飛ばす
- 空行になるまで読み取る
- フォントや罫線などの書式がある表を読み取る
- 上部の余白を除いて読み取る
- 左側に余白のある表を読み取る
- まとめ
先頭カラムが空欄でない行だけ読み取る
以下の「社員ID」つまりA列が空欄でない行のみを読み取るケースを考えます。
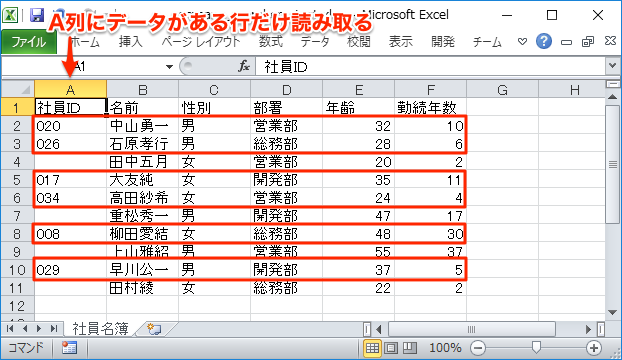
まず何も処理しないで、単純にiter_rows()で1行ずつ読み取ってみます。1行目はヘッダーなので、min_row=2を指定しています。
# xlrow_reader1.py
import openpyxl
wb = openpyxl.load_workbook("company_members_test.xlsx")
ws = wb.worksheets[0]
for row in ws.iter_rows(min_row=2):
values = []
for col in row:
values.append(col.value)
print(values)
すると以下のように、空欄のセルの値(.value)はNoneになるのが分かります。
# 出力結果['020', '中山勇一', '男', '営業部', 32, 10] ['026', '石原孝行', '男', '総務部', 28, 6] [None, '田中五月', '女', '営業部', 20, 2] ['017', '大友純', '女', '開発部', 35, 11] ['034', '高田紗希', '女', '営業部', 24, 4] [None, '重松秀一', '男', '開発部', 47, 17] ['008', '柳田愛結', '女', '総務部', 48, 30] [None, '上山雅紹', '男', '営業部', 55, 37] ['029', '早川公一', '男', '開発部', 37, 5] [None, '田村綾', '女', '総務部', 22, 2]
そこで、以下のようにA列の値(row[0].value)がNoneである行はcontinueでループをスキップすれば、読み込まないようにできます。
...
for row in ws.iter_rows(min_row=2):
if row[0].value is None:
continue
values = []
for col in row:
values.append(col.value)
print(values)
# 出力結果['020', '中山勇一', '男', '営業部', 32, 10] ['026', '石原孝行', '男', '総務部', 28, 6] ['017', '大友純', '女', '開発部', 35, 11] ['034', '高田紗希', '女', '営業部', 24, 4] ['008', '柳田愛結', '女', '総務部', 48, 30] ['029', '早川公一', '男', '開発部', 37, 5]
スペースが入力されているセルを見分ける方法
空欄のセルの値はNoneになりますが、空白文字(スペース)は文字列データです。そのため、A列に半角スペースが1つあるだけで、以下のようにその行は読み込まれてしまいます。
['020', '中山勇一', '男', '営業部', 32, 10]
['026', '石原孝行', '男', '総務部', 28, 6]
[' ', '田中五月', '女', '営業部', 20, 2]
['017', '大友純', '女', '開発部', 35, 11]
...
そこで、空白文字の場合も読み飛ばすために、以下のようにnot str(row[0].value).strip()をif文の条件にorで追加します。これにより、空白文字の場合はstrip()により「空文字」になり、頭にnotが付いているので、Trueに評価されます。
...
for row in ws.iter_rows(min_row=2):
if row[0].value is None or not str(row[0].value).strip():
continue
values = []
for col in row:
values.append(col.value)
print(values)
is_empty()関数:空欄セルかどうかを見分ける(空白文字入力も含む)
以下のように空欄セルと空白文字を見分ける関数として定義し再利用できるようにしておきます。
def is_empty(cell):
return cell.value is None or not str(cell.value).strip()
空欄のセルがある行は読み飛ばす
以下のように空欄のセルがある行は読み込まないケースをプログラミングします。つまり、1つでも項目がない不完全はデータは採用しない場合です。
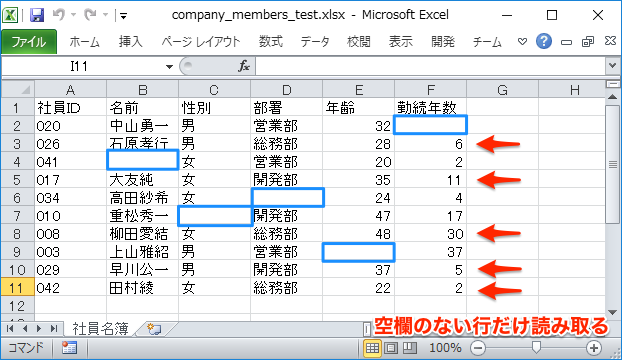
Pythonのコードは以下のように、前出のis_empty()関数と組み込みのany()関数を用いて、空欄セルのある行ではループをスキップさせています。
# xlrow_skip_any_empty.py
import openpyxl
def is_empty(cell):
return cell.value is None or not str(cell.value).strip()
wb = openpyxl.load_workbook("company_members_test.xlsx")
ws = wb.worksheets[0]
for row in ws.iter_rows(min_row=2):
if any(is_empty(c) for c in row):
continue
values = []
for col in row:
values.append(col.value)
print(values)
実行すると以下のように空欄セルを含まない行だけが出力されます。
['026', '石原孝行', '男', '総務部', 28, 6]
['017', '大友純', '女', '開発部', 35, 11]
['008', '柳田愛結', '女', '総務部', 48, 30]
['029', '早川公一', '男', '開発部', 37, 5]
['042', '田村綾', '女', '総務部', 22, 2]
組み込み関数 any()
any()は、Pythonの組み込み関数 なので、インポートしないですぐ使えます。以下のようにリストに1つでもTrueの要素がある時にTrueを返します。
>>> a_lst = [False, False, True, False]
>>> any(a_lst)
True
>>> b_lst = [False, False, False, False]
>>> any(b_lst)
False
今回のコードでは、リスト内包表記を用いて1行分のセルが空欄かどうか「bool型のリスト」を作成し、1つでも空欄(つまり、is_empty()がTrueを返す)のセルがあれば、continueでループをスキップしています。
空行になるまで読み取る
以下のように平均などの集計のための行が余白を挟んで下にある場合を考えます。iter_rows()はデータがある行までループしますので、そのままでは最終行まで読み取ってしまいます。
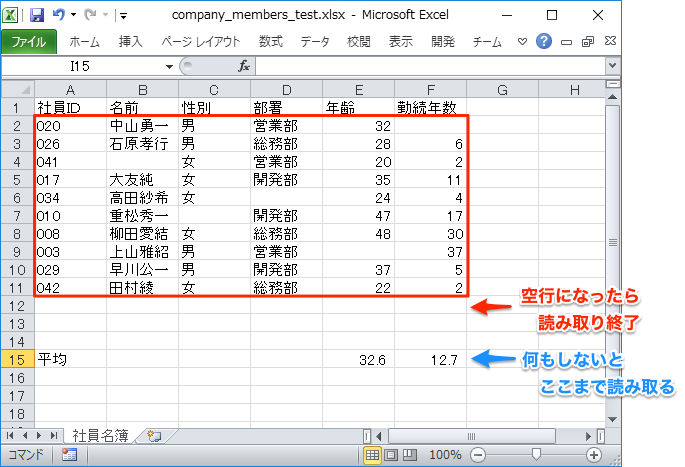
そこで、以下のように「空行」になったら、読み取りのループをbreakで中止します。空行の判定は、前出のis_empty()関数と組み込みのall()関数を用いて、1行分のセルがすべて空欄になるかで見分けます。
# xlrow_stop_all_empty.py
import openpyxl
def is_empty(cell):
return cell.value is None or not str(cell.value).strip()
wb = openpyxl.load_workbook("company_members_test.xlsx")
ws = wb.worksheets[0]
for row in ws.iter_rows(min_row=2):
if all(is_empty(c) for c in row):
break
values = []
for col in row:
values.append(col.value)
print(values)
実行すると以下のようにデータ行の最後までしか読み込まれません。
['020', '中山勇一', '男', '営業部', 32, None]
['026', '石原孝行', '男', '総務部', 28, 6]
['041', None, '女', '営業部', 20, 2]
(中略)
['029', '早川公一', '男', '開発部', 37, 5]
['042', '田村綾', '女', '総務部', 22, 2]
組み込み関数 all()
all()は、Pythonの組み込み関数 なので、インポートしないですぐ使えます。以下のようにリストのすべての要素がTrueになる時にTrueを返します。
>>> a_lst = [False, False, True, False]
>>> all(a_lst)
False
>>> b_lst = [True, True, True, True]
>>> all(b_lst)
True
今回は、リスト内包表記を用いて1行分のセルが空欄かどうか「bool型のリスト」を作成し、すべてが空欄(つまり、is_empty()がTrueを返す)であれば、breakでループを中止しています。
フォントや罫線などの書式がある表を読み取る
iter_rows()は、中身が空欄でも書式が設定されているセルがあると、その行まで読み取ります。以下のように下の空欄部分に太字が設定されているだけでそこまで読み取ります。中央揃えや罫線などのほかの書式でも同様です。
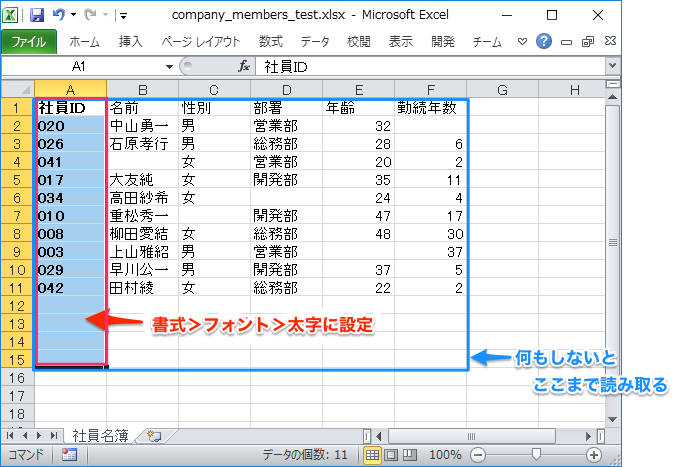
そのため、不要な行データを読み込みたくない場合は、上記のように空行になったら読み取りを中止するなどの措置が必要になります。
エクセルの「セルの書式」とは
標準や数値などの表示形式、セル内の文字の配置、フォント、罫線、塗りつぶし、保護、これらすべてが書式です。
上部の余白を除いて読み取る
以下のように表データが何行目から始めるのか分からない場合を考えてみます。
iter_rows()では、開始行をキーワード引数min_rowで指定できますが、シートの1行目から数えて何行目かが既知でないといけません。
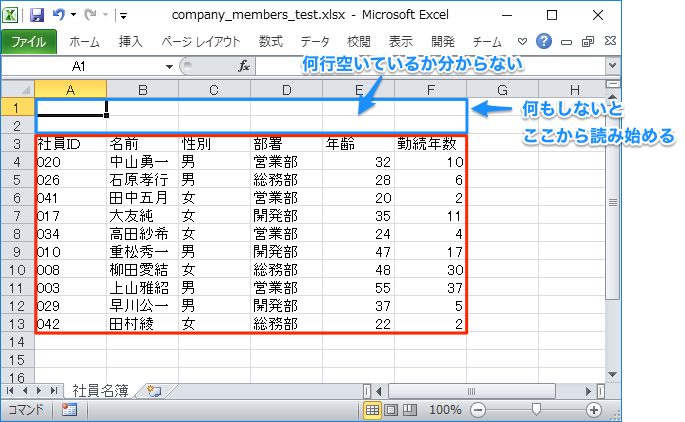
そこで、以下のようなcount_top_empty_row()関数を作成して、上部に空行がいくつ連続するかをカウントすることで開始行を把握します。その値にヘッダーの分の「1」を足した値をmin_rowに指定します。
# xlrow_top_empty.py
import openpyxl
def is_empty(cell):
return cell.value is None or not str(cell.value).strip()
def count_top_empty_row(sheet):
count = 0
for r in sheet:
if all(is_empty(c) for c in r):
count = count + 1
else:
break
return count
wb = openpyxl.load_workbook("company_members_test.xlsx")
ws = wb.worksheets[0]
# 開始行番号(=空行カウント数に「1」を足す)
start_row = count_top_empty_row(ws) + 1
for row in ws.iter_rows(min_row=start_row + 1):
values = []
for col in row:
values.append(col.value)
print(values)
count_top_empty_row()関数:上部の空行の数をカウントする
前述のall()を用いた空行を見分けるコードを活用して、以下のような関数を作成しています。
def count_top_empty_row(sheet):
count = 0
for r in sheet:
if all(is_empty(c) for c in r):
count = count + 1
else:
break
return count
openpyxlでは、シートのmin_rowでデータの開始行を取得することができます。しかし、書式がどこかにあるとそこから認識してしまいます。この関数ならセルが空欄かで見分けることができます。
# 書式が全くないシートであればこれでも可能
start_row = ws.min_row
左側に余白のある表を読み取る
さらに左側に何列空いているのか分からない場合について考えます。
iter_rows()では、開始列をキーワード引数min_colで指定できますが、シートの1列目から数えて何列目かが既知でないといけません。
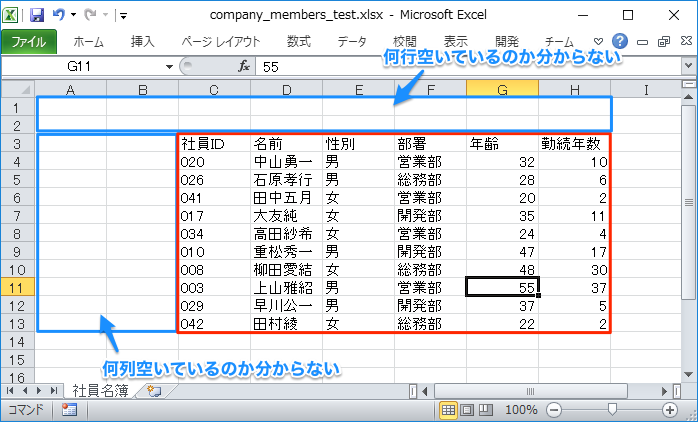
そこで、以下のようなcount_left_empty_cell()関数を作成して、ヘッダー行の左側に空欄のセルがいくつ連続しているかをカウントすることで開始列を把握します。その値をmin_colに指定します。
# xlrow_top_left_empty.py
import openpyxl
def is_empty(cell):
return cell.value is None or not str(cell.value).strip()
def count_top_empty_row(sheet):
count = 0
for r in sheet:
if all(is_empty(c) for c in r):
count = count + 1
else:
break
return count
def count_left_empty_cell(row):
count = 0
for c in row:
if is_empty(c):
count = count + 1
else:
break
return count
wb = openpyxl.load_workbook("company_members_test.xlsx")
ws = wb.worksheets[0]
start_row = count_top_empty_row(ws) + 1
# ヘッダー行で左側の開始列を調べる
header_row = ws[start_row]
start_col = count_left_empty_cell(header_row) + 1
for row in ws.iter_rows(min_row=start_row + 1, min_col=start_col):
values = []
for col in row:
values.append(col.value)
print(values)
count_left_empty_cell()関数:ある行の左側に連続する空欄セルをカウントする
def count_left_empty_cell(row):
count = 0
for c in row:
if is_empty(c):
count = count + 1
else:
break
return count
openpyxlでは、シートのmin_colでデータの開始列を取得することができます。しかし、書式がどこかにあるとそこから認識してしまいます。この関数ならセルが空欄かで見分けることができます。
# 書式が全くないシートであればこれでも可能
start_col = ws.min_col
まとめ
以上のように組み込み関数の any() と all()、さらに今回作成した以下の3つの関数
を組み合わせて工夫すれば、表データがシートの様々な範囲にあっても臨機に対応できます。ぜひ参考にしてください。